How to Convert XML to SQL and JSON
Make sure you have correctly configured the database connection.
On the Local File tab, click on 📄
Enter the name of the new project and click the ➕ button
Now, in the dropdown menu under Project, select the created project and click the 📂 button

Data for the basic-sample project is located in the directory data-samples/basic-sample/example_1.xml
Structure of example_1.xml:
<?xml version="1.0"?>
<customers>
<customer>
<name>Tesla</name>
<keyPerson>Elon Musk</keyPerson>
<UsaResident>Yes</UsaResident>
<foundedYear>2003</foundedYear>
<department>
<name>Tesla Engineering</name>
<address>1501 Page Mill Road Palo Alto, Framingham, USA</address>
</department>
<department>
<name>Gigafactory Texas</name>
<address>1 Tesla Road Austin, TX 78725, USA</address>
</department>
</customer>
<customer>
<name>Boston Dynamics</name>
<keyPerson>Robert Playter</keyPerson>
<UsaResident>Yes</UsaResident>
<foundedYear>1992</foundedYear>
<department>
<name>Headquarters</name>
<address>200 Smith St, Waltham, USA</address>
</department>
</customer>
<customer>
<name>Bank of Korea</name>
<keyPerson>Kim Seong Tae</keyPerson>
<UsaResident>No</UsaResident>
<foundedYear>1950</foundedYear>
<department>
<name>Main Department</name>
<address>Sejong-daero, Jung-gu, Seoul, South Korea</address>
</department>
</customer>
</customers>
After opening the project, the bottom row of buttons will be activated, allowing you to add and delete sections and subsections.
To start, you will need to create a section and a subsection.
Each individual section represents a logically isolated type of document.
Each subsection represents a subtype of the document. This is usually required for cases where there is some variability in the structure within a separate logical type of documents.
The number of types (sections) and subtypes (subsections) is not limited.
For each type (section), you can specify separate parsing rules. For all subtypes (subsections) within a type (section), parsing rules are common.
Within the project, it is necessary to create at least one type and one subtype.

After that, you need to place a punch on the selected subsection and describe the desired structure of the extracted data in the format of an intermediate representation.
In XML (eXtensible Markup Language), all elements are nodes.
All nodes that need to be represented as tables (or as JSON arrays) must have a parent that will be used as the table name (or array name in the case of JSON). Example:
parent_name: [ ; container that will be used as name of table or name of json array
some_node: [ ; node corresponding to a real node in XML
]
]
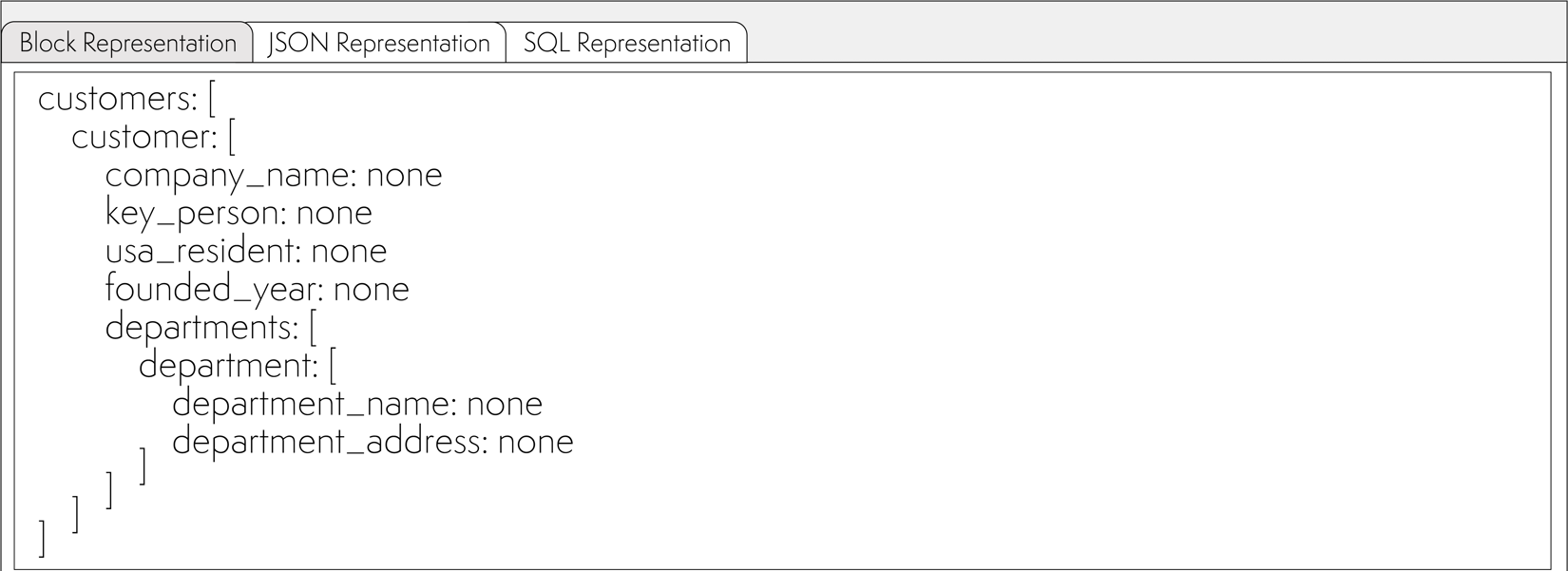
Each value should be represented in the format: node_name: none
If your data structure is such that the root starts not with blocks, but with values, then the name of the table for the root will be the name of the subsection.
If some data is not needed to be extracted, simply do not describe it in the specified structure. In the example, we extract all the data. As a result, we should have the following document description:
The names in the intermediate representation do not necessarily have to match the names in the original XML file. However, these names must exactly match the structure of tables in the relational database into which the data is unloaded.
All further manipulations will be tied to the names of the intermediate representation, so it is necessary for the names not to be repeated. It is good practice to give names that allow understanding the parent of a particular tag. Not
name: none, but department_name: none
Text representation of the example data:
customers: [
customer: [
company_name: none
key_person: none
usa_resident: none
founded_year: none
departments: [
department: [
department_name: none
department_address: none
]
]
]
]
It is important to remember that this description will be translated into tables exactly as described. The names of the parent nodes will be used as table names.
Keep in mind that SmartXML allows you to build missing parent tags if they are implied but missing in the original XML.
You may have noticed that in the original XML, customer has a parent node customers, but department doesn't have a parent departments, although it is clearly implied.
Therefore, let's describe the intermediate representation as if all sections were present.
For the given example, the correct table structure (SQLite notation) would be: customers and departments
CREATE TABLE customers (
id INTEGER PRIMARY KEY AUTOINCREMENT,
company_name TEXT,
key_person TEXT
usa_resident TEXT,
founded_year INTEGER
);
CREATE TABLE departments (
id Integer PRIMARY KEY AUTOINCREMENT,
department_name Text,
department_address Text
);
Next, it is necessary to establish a correspondence between elements of the XML tree (paths) and names in the intermediate representation.
To do this, you need to click on the Morphology button. After that, you have to match the elements from the intermediate representation with the chains of XML tags:
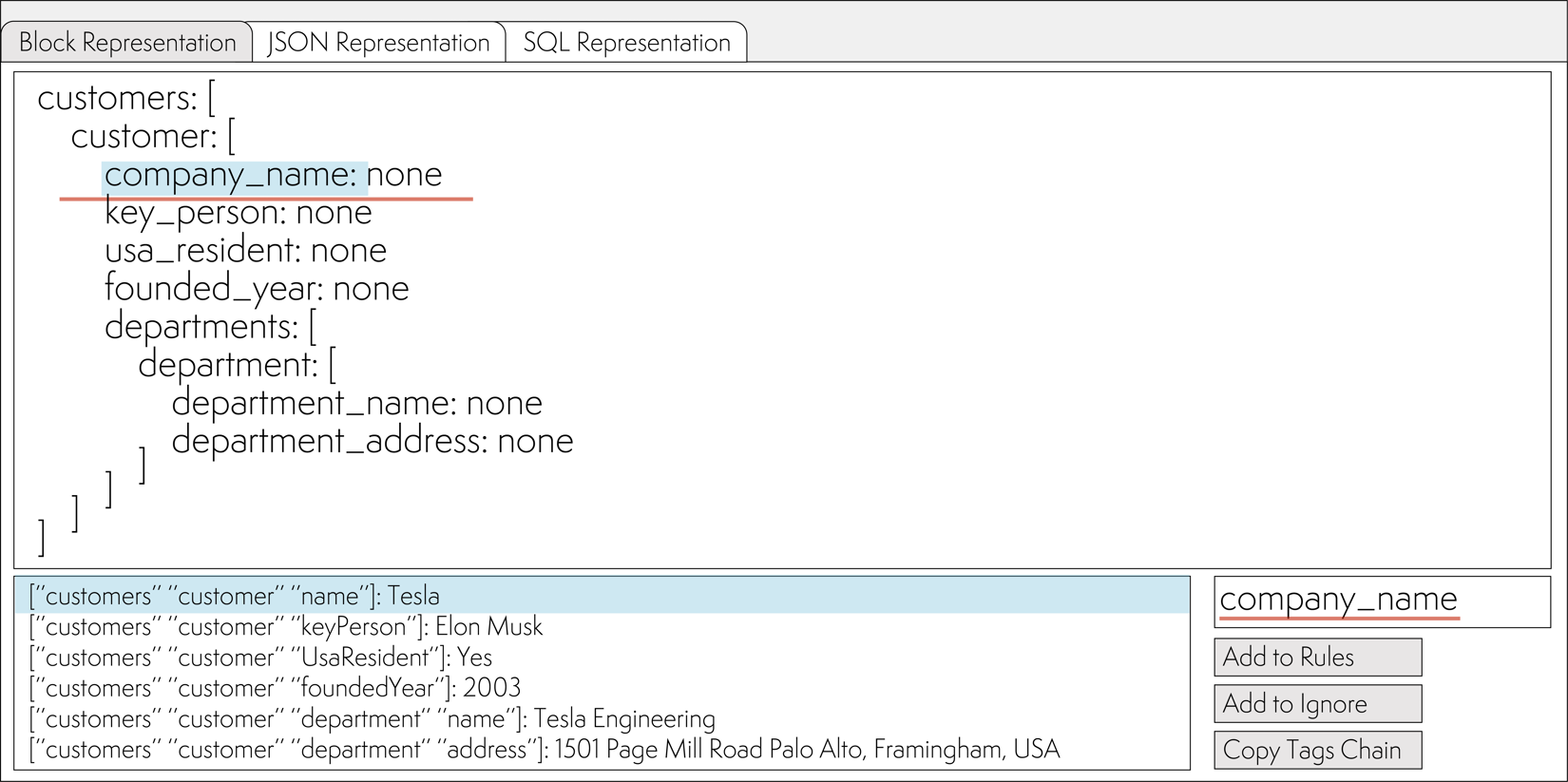
Add each chain to the rules with the Add to Rules button. Repeat the operation for all tags.
Editing the tag chain is possible on the Rules ⮞ Tags Matching tab
Editing the list of ignored tag chains is possible on the Rules ⮞ Ignored Tags tab
After that, switch to the Rules ⮞ Grow Rules tab and specify the names of nodes in the SmartXML schema. When encountering these nodes, SmartXML will need to build the intermediate representation.
In the left column, specify the name of the node from the intermediate representation. In the right column, specify how the node is named in XML.
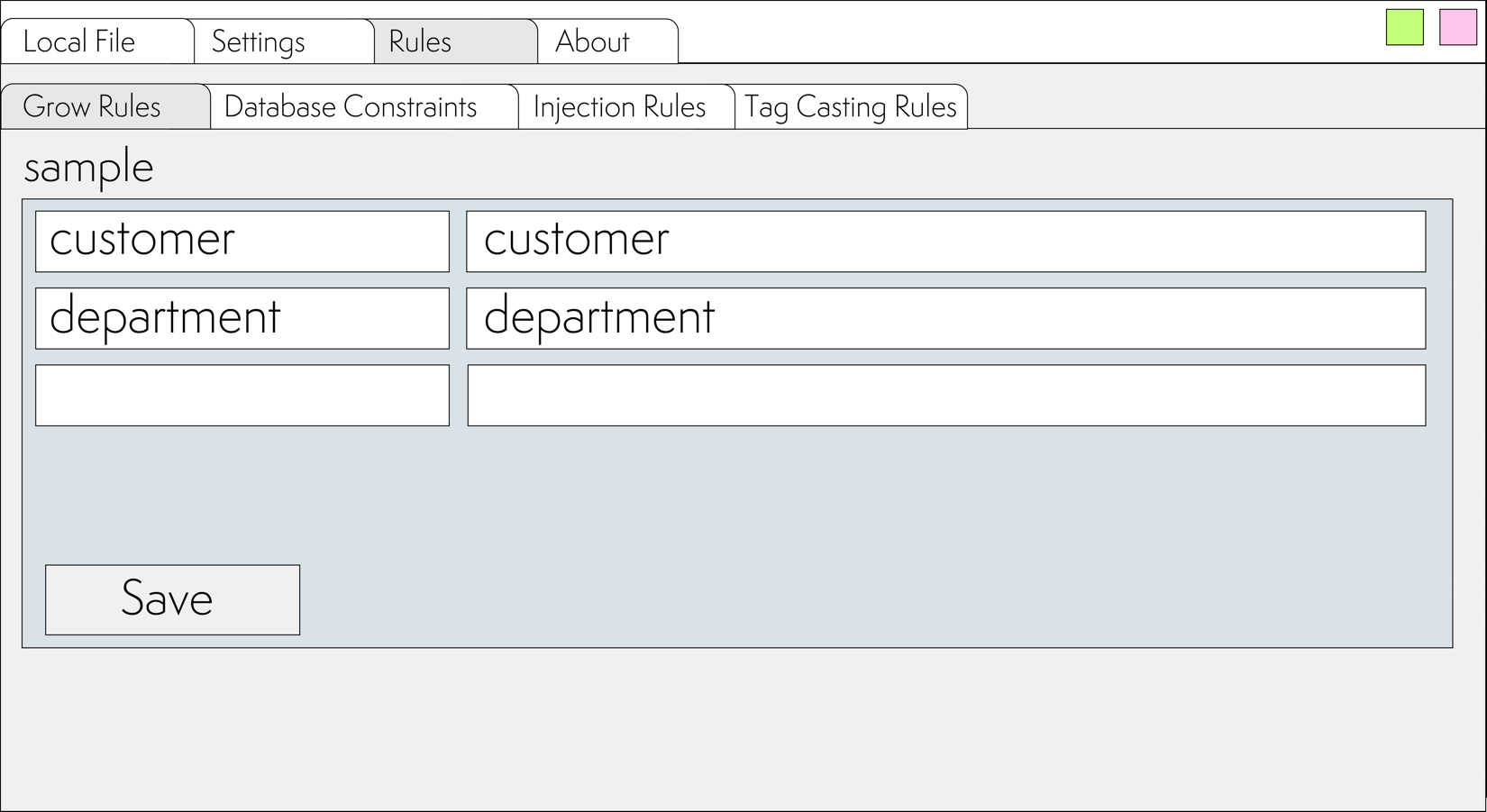
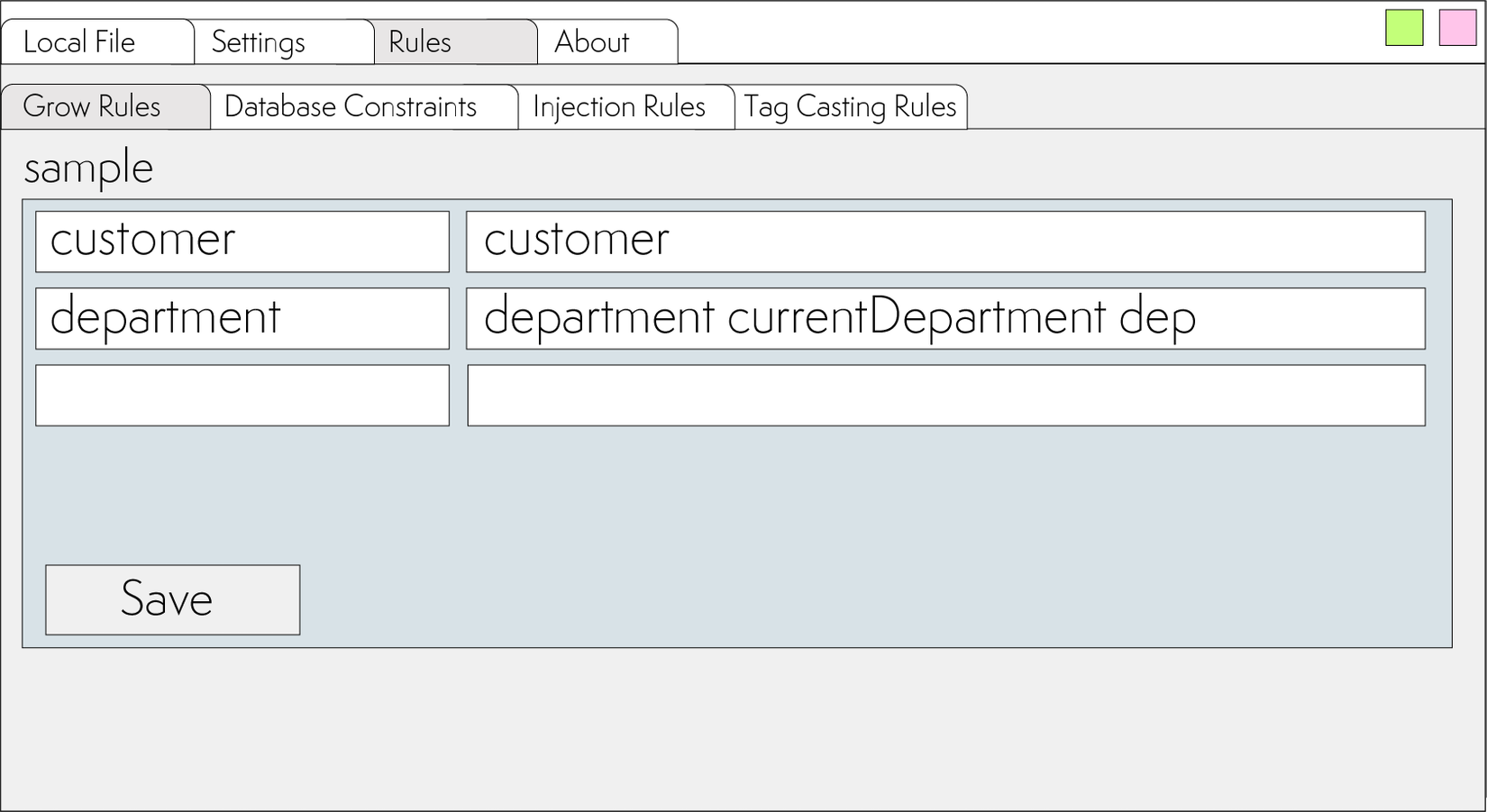
For each node, you can add an unlimited number of writing options. So, if in the original XML we had the following naming variants:
<department>
<name>Tesla Engineering</name>
<address>1501 Page Mill Road Palo Alto, Framingham, USA</address>
</department>
<currentDepartment>
<name>Tesla Engineering</name>
<address>1501 Page Mill Road Palo Alto, Framingham, USA</address>
</currentDepartment>
<dep>
<name>Tesla Engineering</name>
<address>1501 Page Mill Road Palo Alto, Framingham, USA</address>
</dep>
The rule would look like this:
Now, after clicking the Parse button on the Block Representation tab, we will get the following representation:
[customers: [customer: [
company_name: "Tesla"
key_person: "Elon Musk"
usa_resident: "Yes"
founded_year: "2003"
departments: [department: [
department_name: "Tesla Engineering"
department_address: "1501 Page Mill Road Palo Alto, Framingham, USA"
] department: [
department_name: "Gigafactory Texas"
department_address: "1 Tesla Road Austin, TX 78725, USA"
]]
] customer: [
company_name: "Boston Dynamics"
key_person: "Robert Playter"
usa_resident: "Yes"
founded_year: "1992"
departments: [department: [
department_name: "Headquarters"
department_address: "200 Smith St, Waltham, USA"
]]
] customer: [
company_name: "Bank of Korea"
key_person: "Kim Seong Tae"
usa_resident: "No"
founded_year: "1950"
departments: [department: [
department_name: "Main Department"
department_address: "67, Sejong-daero, Jung-gu, Seoul, South Korea"
]]
]]]
As you can see, SmartXML added nodes.
Note: if you need to add sequential numbers to nodes that are missing in the original data, specify the list of these nodes separated by a space on the Inject Rules⮞Enumerate nodes
The tag name with the number is always fixed: item_number
So, in the provided example, setting this field in department will result in the generation of the following intermediate representation:
Enumerate nodes example
[customers: [customer: [
company_name: "Tesla"
key_person: "Elon Musk"
usa_resident: "Yes"
founded_year: "2003"
departments: [department: [
item_number: 1
department_name: "Tesla Engineering"
department_address: "1501 Page Mill Road Palo Alto, Framingham, USA"
] department: [
item_number: 2
department_name: "Gigafactory Texas"
department_address: "1 Tesla Road Austin, TX 78725, USA"
]]
] customer: [
company_name: "Boston Dynamics"
key_person: "Robert Playter"
usa_resident: "Yes"
founded_year: "1992"
departments: [department: [
item_number: 1
department_name: "Headquarters"
department_address: "200 Smith St, Waltham, USA"
]]
] customer: [
company_name: "Bank of Korea"
key_person: "Kim Seong Tae"
usa_resident: "No"
founded_year: "1950"
departments: [department: [
item_number: 1
department_name: "Main Department"
department_address: "67, Sejong-daero, Jung-gu, Seoul, South Korea"
]]
]]]
Now the obtained representation can be transformed into both JSON and SQL.
To convert to JSON in the interface, click the to JSON button, and on the JSON Representation tab, the following result will be presented:
{
"customers": [
{
"company_name": "Tesla",
"key_person": "Elon Musk",
"usa_resident": "Yes",
"founded_year": "2003",
"departments": [
{
"department_name": "Tesla Engineering",
"department_address": "1501 Page Mill Road Palo Alto, Framingham, USA"
},
{
"department_name": "Gigafactory Texas",
"department_address": "1 Tesla Road Austin, TX 78725, USA"
}
]
},
{
"company_name": "Boston Dynamics",
"key_person": "Robert Playter",
"usa_resident": "Yes",
"founded_year": "1992",
"departments": [
{
"department_name": "Headquarters",
"department_address": "200 Smith St, Waltham, USA"
}
]
},
{
"company_name": "Bank of Korea",
"key_person": "Kim Seong Tae",
"usa_resident": "No",
"founded_year": "1950",
"departments": [
{
"department_name": "Main Department",
"department_address": "67, Sejong-daero, Jung-gu, Seoul, South Korea"
}
]
}
]
}
Pay attention that nodes containing arrays are correctly generated. This happened thanks to the configuration of Grow Rules. Otherwise, in the following structure:
<departments>
<department></department>
</departments>
SmartXML wouldn't be able to correctly recognize whether departments is an object {} or if departments is an array of objects: [{},{}]
To convert to SQL, simply press the to SQL button, and the intermediate representation will be transformed into a SQL statement for insertion into the database:
INSERT INTO customers ("company_name", "key_person", "usa_resident", "founded_year")
VALUES ('Tesla', 'Elon Musk', 'tag-value', '2003'),
('Boston Dynamics', 'Robert Playter', 'Yes', '1992'),
('Bank of Korea', 'Kim Seong Tae', 'No', '1950');
INSERT INTO departments ("department_name", "department_address")
VALUES ('Tesla Engineering', '1501 Page Mill Road Palo Alto, Framingham, USA'),
('Gigafactory Texas', '1 Tesla Road Austin, TX 78725, USA'),
('Headquarters', '200 Smith St, Waltham, USA'),
('Main Department', '67, Sejong-daero, Jung-gu, Seoul, South Korea');
SQL expressions are generated with consideration for multiple VALUES at once.
However, if we execute the specified insert statement multiple times, we will get unwanted duplicate records in the tables.
To prevent the addition of duplicates, you can use a special condition to prevent the insertion of repeating values: ON CONFLICT DO UPDATE
To do this, you need to:
1. Set a uniqueness constraint on the required columns in the database table
2. Specify the names of these columns in the SmartXML settings
After adding a constraint to prevent the insertion of identical company_name values, the customers table will look like this:
CREATE TABLE customers (
id Integer PRIMARY KEY AUTOINCREMENT,
company_name Text,
key_person Text,
usa_resident Text,
founded_year Integer,
CONSTRAINT "uniq_company_name" UNIQUE ("company_name")
);
Now you need to specify these constraints in the SmartXML settings. To do this, go to the Rules ⮞ Database Constraints tab and specify the table name and the name of one or more columns for which uniqueness constraints are set.
In the left column, specify the table name. In the right column, specify the names of the columns for which uniqueness constraints are set.
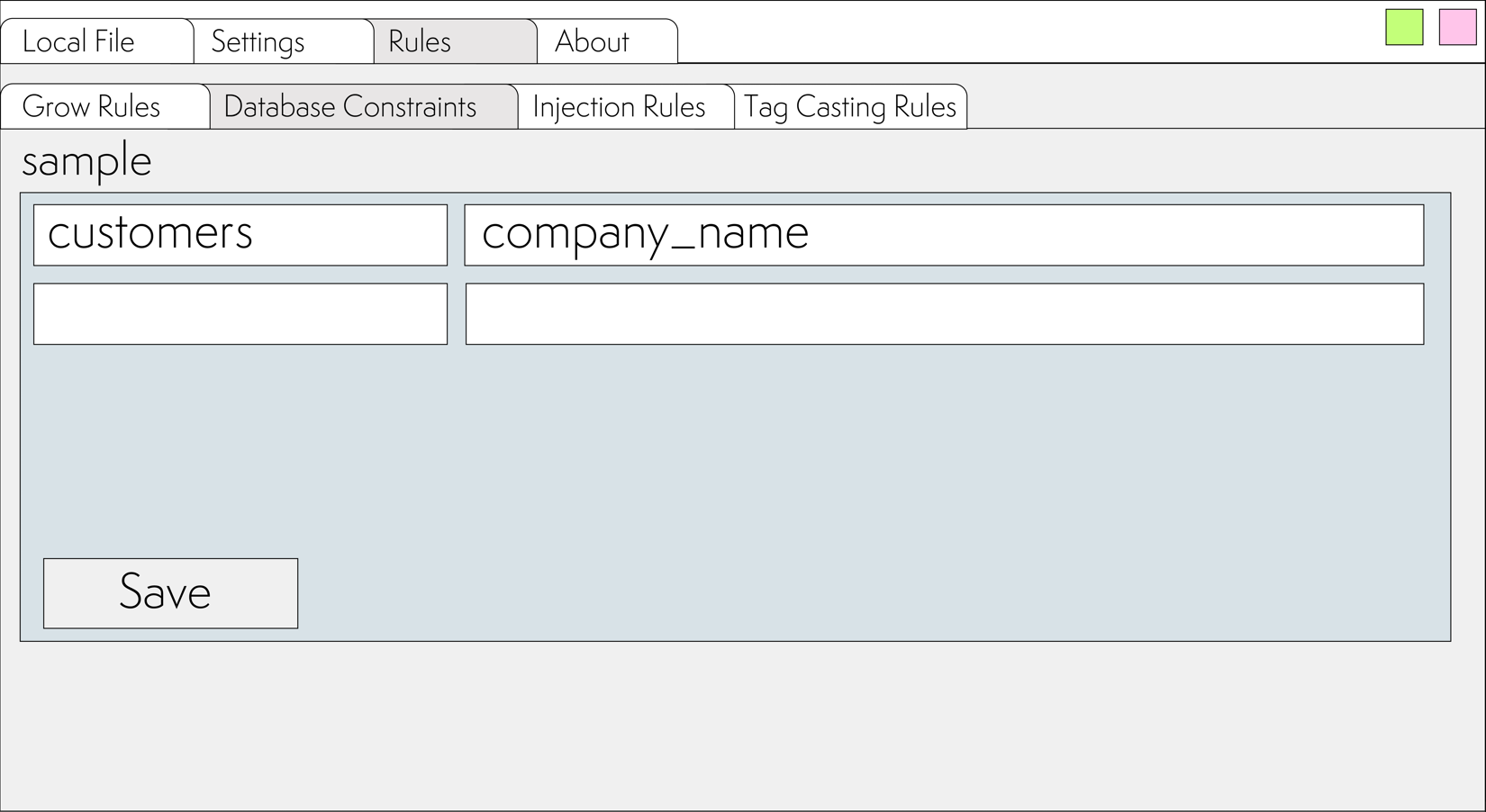
Now, after clicking the to SQL button, an expression for the customers table will be generated, taking into account the ON CONFLICT:
INSERT INTO customers ("company_name", "key_person", "usa_resident", "founded_year")
VALUES
('Tesla', 'Elon Musk', 'Yes', '2003'),
('Boston Dynamics', 'Robert Playter', 'Yes', '1992'),
('Bank of Korea', 'Kim Seong Tae', 'No', '1950')
ON CONFLICT ("company_name")
DO UPDATE SET
"company_name" = EXCLUDED."company_name",
"key_person" = EXCLUDED."key_person",
"usa_resident" = EXCLUDED."usa_resident",
"founded_year" = EXCLUDED."founded_year";
INSERT INTO departments ("department_name", "department_address")
VALUES
('Tesla Engineering', '1501 Page Mill Road Palo Alto, Framingham, USA'),
('Gigafactory Texas', '1 Tesla Road Austin, TX 78725, USA'),
('Headquarters', '200 Smith St, Waltham, USA'),
('Main Department', '67, Sejong-daero, Jung-gu, Seoul, South Korea');
However, no constraints are currently set for the departments table.
Let's assume we want to prevent the insertion of duplicate records with the same combination of company_name and department_name into it. However, in the original XML, the company_name is located one level above and relates to the customers node.
To achieve this, let's set up the forwarding of the parent's name to the child. Go to Rules ⮞ Injection Rules
In case a field needs to be passed to all children, you can use the Inject tag to every children option and specify the names of the tags that need to be passed down one level, separated by spaces.
However, you can also specify specific names of child nodes into which the specified field should be passed.
In this case, the company_name needs to be passed to the department node. (Important: specify the name of the final node, so it's not departments, but department)
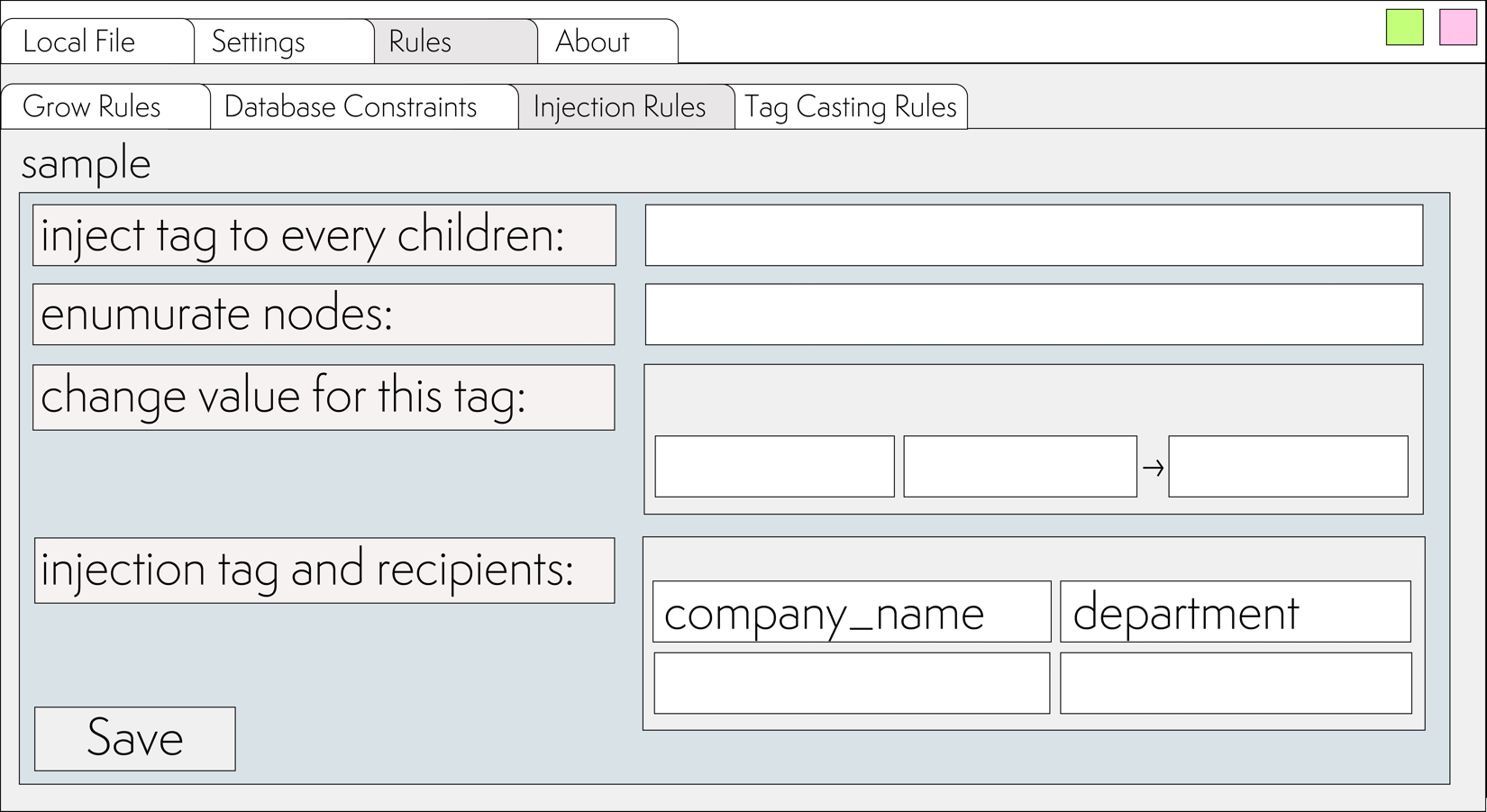
Now, the intermediate representation will look like this:
[customers: [customer: [
company_name: "Tesla"
key_person: "Elon Musk"
usa_resident: "Yes"
founded_year: "2003"
departments: [department: [
department_name: "Tesla Engineering"
department_address: "1501 Page Mill Road Palo Alto, Framingham, USA"
] department: [
department_name: "Gigafactory Texas"
department_address: "1 Tesla Road Austin, TX 78725, USA"
]]
] customer: [
company_name: "Boston Dynamics"
key_person: "Robert Playter"
usa_resident: "Yes"
founded_year: "1992"
departments: [department:
department_name: "Headquarters"
department_address: "200 Smith St, Waltham, USA"
]]
] customer: [
company_name: "Bank of Korea"
key_person: "Kim Seong Tae"
usa_resident: "No"
founded_year: "1950"
departments: [department: [
department_name: "Main Department"
department_address: "67, Sejong-daero, Jung-gu, Seoul, South Korea"
]]
]]]
As you can see, each node in the intermediate representation department now has the field: company_name:
department: [
company_name: "Bank of Korea"
department_name: "Main Department"
department_address: "67, Sejong-daero, Jung-gu, Seoul, South Korea"
]
Add the company_name column to the departments table and specify unique constraints for the columns: company_name and department_name, resulting in the following table:
CREATE TABLE departments (
id Integer PRIMARY KEY AUTOINCREMENT,
department_name Text,
department_address Text,
company_name Text,
CONSTRAINT "uniq_company_name" UNIQUE ("company_name", "department_name")
);
In the application settings, set constraints for the tables:
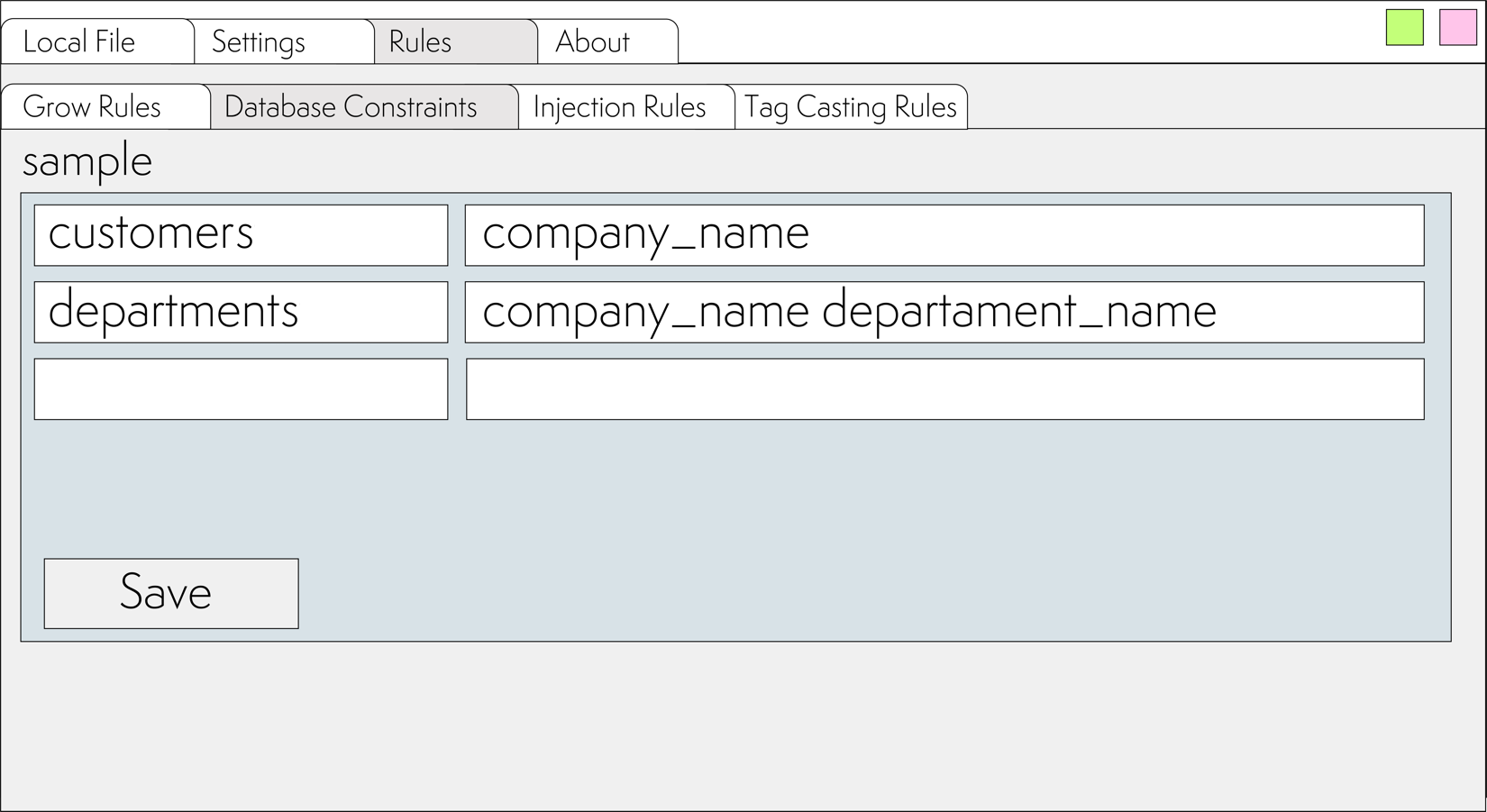
Now, after pressing the to SQL button, the following SQL expression preventing duplicates insertion into both tables will be generated:
INSERT INTO customers ("company_name", "key_person", "usa_resident", "founded_year")
VALUES
('Tesla', 'Elon Musk', 'Yes', '2003'),
('Boston Dynamics', 'Robert Playter', 'Yes', '1992'),
('Bank of Korea', 'Kim Seong Tae', 'No', '1950')
ON CONFLICT ("company_name")
DO UPDATE SET
"company_name" = EXCLUDED."company_name",
"key_person" = EXCLUDED."key_person",
"usa_resident" = EXCLUDED."usa_resident",
"founded_year" = EXCLUDED."founded_year";
INSERT INTO departments ("company_name", "department_name", "department_address")
VALUES
('Tesla, 'Tesla Engineering', '1501 Page Mill Road Palo Alto, Framingham, USA'),
('Tesla, 'Gigafactory Texas', '1 Tesla Road Austin, TX 78725, USA'),
('Boston Dynamics, 'Headquarters', '200 Smith St, Waltham, USA'),
('Bank of Korea, 'Main Department', '67, Sejong-daero, Jung-gu, Seoul, South Korea')
ON CONFLICT ("company_name", "department_name")
DO UPDATE SET
"company_name" = EXCLUDED."company_name",
"department_name" = EXCLUDED."department_name",
"department_address" = EXCLUDED."department_address";
Please note that by default, all tag values are extracted as text. That is, if the tag value is, for example, 123, it will be extracted as a string "123".
For the correct processing of different types, SmartXML provides several mechanisms, described in a separate article.
In cases where the data can be unambiguously interpreted as integer, float, or bool, on the Rules⮞Tag Casting Rules tab, it is sufficient to specify which tags should be cast to which types.
In our example, we will cast founded_year to integer, and usa_resident to bool.
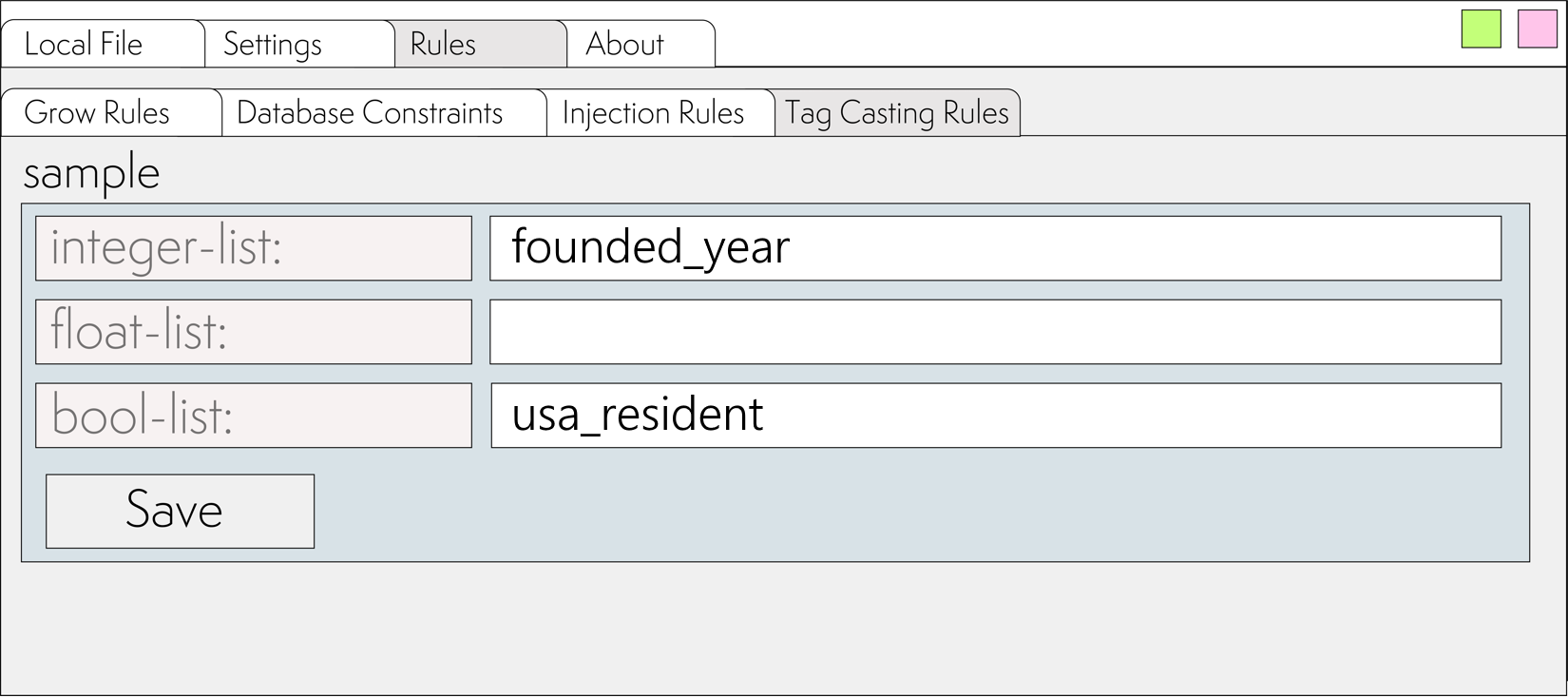
Now, after clicking the to SQL button, SQL will be generated with type casting taken into account:
INSERT INTO customers ("company_name", "key_person", "usa_resident", "founded_year")
VALUES
('Tesla', 'Elon Musk', true, 2003),
('Boston Dynamics', 'Robert Playter', true, 1992),
('Bank of Korea', 'Kim Seong Tae', false, 1950)
ON CONFLICT ("company_name")
DO UPDATE SET
"company_name" = EXCLUDED."company_name",
"key_person" = EXCLUDED."key_person",
"usa_resident" = EXCLUDED."usa_resident",
"founded_year" = EXCLUDED."founded_year";
INSERT INTO departments ("company_name", "department_name", "department_address")
VALUES
('Tesla', 'Tesla Engineering', '1501 Page Mill Road Palo Alto, Framingham, USA'),
('Tesla', 'Gigafactory Texas', '1 Tesla Road Austin, TX 78725, USA'),
('Boston Dynamics', 'Headquarters', '200 Smith St, Waltham, USA'),
('Bank of Korea', 'Main Department', '67, Sejong-daero, Jung-gu, Seoul, South Korea')
ON CONFLICT ("company_name", "department_name")
DO UPDATE SET
"company_name" = EXCLUDED."company_name",
"department_name" = EXCLUDED."department_name",
"department_address" = EXCLUDED."department_address";
Structure of project directories and files:
basic-sample
├── ignores
│ └── sample.txt
├── rules
│ ├── complex-extract-rules.red
│ │ sample: []
│ ├── db-constraints-rules.red
│ │ sample: [
│ │ customers: [company_name] ; The uniqueness constraint must be set for column: company_name
│ │ departments: [company_name department_name] ; For columns company_name department_name must be set composite key uniqueness restriction
│ │ ]
│ ├── grow-rules.red
│ │ sample: [
│ │ customer: ["customer"] ; key - name in intermediate representation, value - variants (one or more) of key writing in XML
│ │ department: ["department"] ; key - name in intermediate representation, value - variants (one or more) of key writing in XML
│ │ ]
│ ├── injection-rules.red
│ │ sample: [
│ │ inject-tag-to-every-children: []
│ │ enumerate-nodes: [department] ; if need to add sequential numbers to nodes. Always fixed name: item_number
│ │ injection-tag-and-recipients: [
│ │ company_name: [department] ; company_name will be passed to the department node. One or more lower-level nodes can be specified
│ │ ]
│ │ ]
│ ├── tags-casting-rules.red
│ │ sample: [
│ │ integer-list: [[to-integer to-float] [founded_year]] ; founded_year will be casted to integer
│ │ float-list: [[to-float] []]
│ │ bool-list: [[reduce to-word] [usa_resident]] ; usa_resident will be casted to logical (true/false)
│ │ ]
│ └── tags-matching-rules.red
│ #[
│ sample: #[
│ company_name: [
│ "customers customer name"
│ ]
│ key_person: [
│ "customers customer keyPerson"
│ ]
│ usa_resident: [
│ "customers customer UsaResident"
│ ]
│ founded_year: [
│ "customers customer foundedYear"
│ ]
│ department_name: [
│ "customers customer department name"
│ ]
│ department_address: [
│ "customers customer department address"
│ ]
│ ]
│ ]
├── templates
│ └── data-templates.red
│ #[
│ sample: #[ ; section name
│ sample: #[ ; subsection name
│ customers: [
│ customer: [
│ company_name: none
│ key_person: none
│ usa_resident: none
│ founded_year: none
│ departments: [
│ department: [
│ department_name: none
│ department_address: none
│ ]
│ ]
│ ]
│ ]
│ ]
│ ]
│ ]
├── config.txt
│ ; allowed combinations: true false "..." none
│
│ job-number: 1 ; default number from job.txt
│ root-xml-folder: "D:/data-samples" ; in case the database stores relative paths without root directory
│ xml-filling-stat: false ; Record occupancy statistics to the database. table: filling_percent_stat should exists
│ ignore-namespaces: true ; Ignore namespaces in XML
│ ignore-tag-attributes: true ;
│ use-same-morphology-for-same-file-name-pattern: false
│ skip-schema-version-tag: true
│ use-same-morphology-for-all-files-in-folder: false
│ delete-data-before-insert: false
│ connect-to-db-at-project-opening: false ; Only when working with the database
│ source-database: "SQLite" ; available values: PostgreSQL/SQLite
│ target-database: "SQLite" ; available values: PostgreSQL/SQLite/NoSQL
│
| ; it is possible to set up notification of unknown tags when persing
│ bot-chatID: "" ;
│ bot-token: ""
│ telegram-notifications: false
│
│ db-driver: ""
│ db-server: "127.0.0.1"
│ db-port: "5432"
│ db-name: "test"
│ db-user: "postgres"
│ db-pass: ""
│
│ sqlite-driver-name: "SQLite3 ODBC Driver" ; check driver name. May vary
│ sqlite-db-path: ""
│
│ nosql-url: "http://localhost:8529/_db/testdb/_api/document/" ; sample for ArangoDB
│ append-subsection-name-to-nosql-url: true ; Some databases (such as ArangoDB) require you to pass the collection name in the URL
│ nosql-login: "root"
│ nosql-pass: "12345"
└── job.txt
job-number: 1 ; number of where-condition. is required to work with the database. In case of multiprocessing, it is overridden via command line arguments for each application instance.
xml-table-name: "xml_files" ; table name where XML references are stored
limit: 1000 ; Number of files requested at a time for processing
order_by: "id ASC" ; sort order
select-fields: [
id xml_path ; mandatory fields must be in each table with xml_files
]
where-condition: [
[] ; SELECT ... WHERE. Recommended to customize from GUI
]