Jobs Settings
Configuring Table Structure
SmartXML operates in single-threaded mode. A Job represents a set of rules that define the selection of XML files for processing. Multiple Job instances are necessary if you need to run more than one instance of SmartXML and provide each with a separate portion of XML to process. Otherwise, one Job is sufficient.
The recommended name for the table containing the source files is xml_files.
The xml_files table can contain any number of columns describing the data. However, it must include the following columns:
-
id- a unique identifier. Cannot beNULL. -
xml_path- the full or relative path to the target XML file. If the path is relative, specify the missing part of the path from the root on the Settings ⮞ General ⮞ XML folder tab. If the path is formed from the names of other columns, you can make thexml_pathcolumn auto-generated using a generated column. Example:ALTER TABLE xml_files ADD COLUMN xml_path VARCHAR(300) GENERATED ALWAYS AS (section_name || '/' || file_type || '/' || file_name) STORED; -
parsing_statuswith typeTEXT/VARCHAR. Indicates the parsing status. Default isNULL. -
processed_datewith typeTEXT/TIMESTAMP WITHOUT TIME ZONEto store the processing time. -
filling_percent_statwith typeNumeric/SmallIntto store the document's filling statistics (corresponding setting must be enabled).
Example of the minimum required table structure for SQLite and PostgreSQL:
CREATE TABLE xml_files (
"id" INTEGER PRIMARY KEY AUTOINCREMENT,
"xml_path" Text,
"parsing_status" Text,
"filling_percent_stat" Numeric,
"processed_date" Text,
CONSTRAINT "unique_id" UNIQUE ("id")
);
CREATE TABLE xml_files (
"id" BigInt primary key generated always as identity,
"xml_path" Character Varying(300),
"parsing_status" Character Varying(50),
"filling_percent_stat" SmallInt,
"processed_date" Timestamp Without Time Zone
);
By default, each Job requests 1000 files for processing. Depending on your needs, this value can be adjusted.
Configuring Job Parameters for Multiprocessor Processing
To configure individual Job settings, go to the Database tab, click the Add button, and add the number of Job instances you plan to process simultaneously.
The number of Job instances should not exceed the number of available processor cores.
For a table with the following structure:
CREATE TABLE xml_files (
"id" Integer PRIMARY KEY AUTOINCREMENT,
"xml_path" Text,
"parsing_status" Text,
"filling_percent_stat" Numeric,
"job_number" Numeric,
"doc_date" Text,
"section_name" Text,
"action_type" Text,
"some_status" Text,
"some_date" Text,
"some_flag" Text,
CONSTRAINT "unique_id" UNIQUE ( "id" )
);
Использование следующих настроек Job:
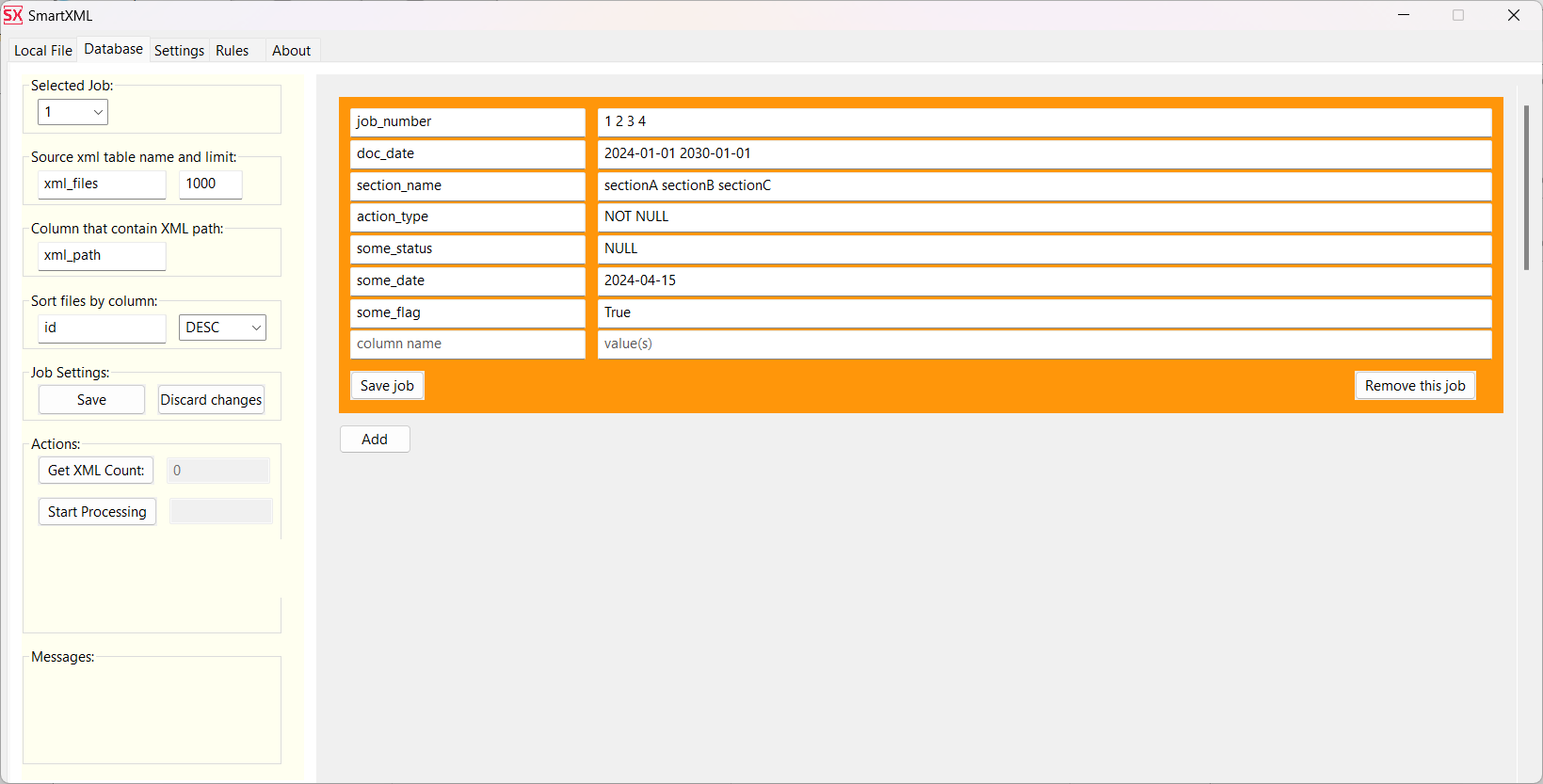
Приведет к генерации следующего запроса на получение задач для обработки
SELECT "id", "xml_path"
FROM xml_files WHERE
parsing_status IS NULL
AND "job_number" IN (1,2,3,4)
AND "doc_date" >= DATE('2024-01-01')
AND "doc_date" <= DATE('2030-01-01')
AND "section_name" IN ('sectionA', 'sectionB', 'sectionC')
AND "action_type" IS NOT NULL
AND "some_status" IS NULL
AND "some_date" = DATE('2024-04-15')
AND "some_flag" IS TRUE
ORDER BY "id" ASC
LIMIT 1000;
Example of creating two Jobs:
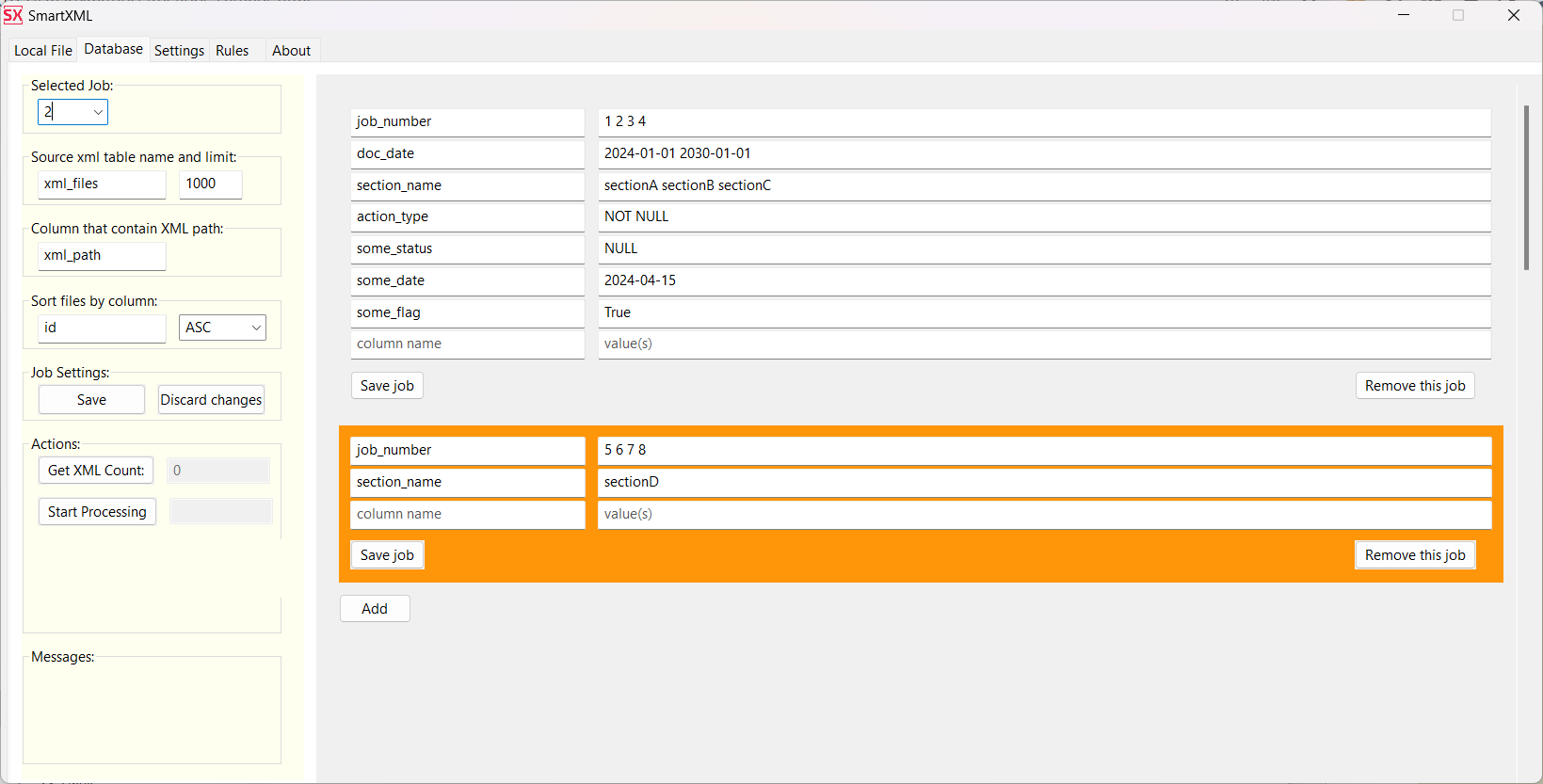
The query to select files for processing that will be generated by the second Job:
SELECT "id", "xml_path"
FROM xml_files WHERE
parsing_status IS NULL
AND "jobNumber" IN (5, 6, 7, 8)
AND "section_name" = 'sectionD'
ORDER BY "id" ASC
LIMIT 1000;
Общий вид сгенерированного job.txt
job-number: 1 xml-table-name: "xml_files" limit: 1000 order_by: "id ASC" select-fields: [ id xml_path ] where-condition: [ [ job_number: [1 2 3 4] doc_date: ["2024-01-01" "2030-01-01"] section_name: [sectionA sectionB sectionC] action_type: "NOT NULL" some_status: "NULL" some_date: ["2024-04-15"] some_flag: True ] [ job_number: [5 6 7 8] section_name: "sectionD" ] ]
Supported formats: integer, string, Date, NULL, NOT NULL, TRUE, FALSE
Note:
- SQLite does not support the
BOOLEANtype. Dateshould have the formatyyyy-mm-dd- Columns
id,parsing_status,xml_pathare not explicitly mentioned in theJob, but as seen in the example, they are included in the query as mandatory.
To save the Job, be sure to click Save Job and Save in the Job Settings menu.