Creating database table patches based on XML
Example is based on the project: credit-forms-unification-sample. The example demonstrates the ability to update fields of a table in an existing database with data extracted from XML documents.
Open the project credit-forms-patching-sample
The table xml_files, which stores references to the original XML files, has the following schema (you can read about the minimal necessary database schema for operation here):
CREATE TABLE xml_files (
"id" Integer PRIMARY KEY AUTOINCREMENT,
"xml_path" Text,
"parsing_status" Text,
"processed_date" Numeric,
"is_patch" Text,
CONSTRAINT "unique_tax_number" UNIQUE (tax_number)
);
Attention:
- In this example, the filling_percent_stat field is missing. Make sure that the corresponding setting Write to DB columns filling stat is turned off.
-
When generating the
UPDATEexpression, theWHEREclause uses the column names on which uniqueness constraints are set. For example:Without this, the generation ofUPDATE credits_forms SET "phone_number" = '+31 20 83115136', "email" = 'lisa.newmail@example.com', "is_married" = 'Married' WHERE "tax_number" ='456-78-9012';UPDATEstatements is not possible. Uniqueness constraints are required both at the database level and in the application settings, as will be shown below.
Overall view of the filled table:
| id | xml_path | parsing_status | processed_date | is_patch |
|---|---|---|---|---|
| 1 | data-samples/credit-forms-patching-sample/barclays.xml | NULL | NULL | NULL |
| 2 | data-samples/credit-forms-patching-sample/barclays_patch.xml | NULL | NULL | true |
| 3 | data-samples/credit-forms-patching-sample/deutschebank.xml | NULL | NULL | NULL |
| 4 | data-samples/credit-forms-patching-sample/deutschebank_patch.xml | NULL | NULL | true |
| 5 | data-samples/credit-forms-patching-sample/rabobank.xml | NULL | NULL | NULL |
| 6 | data-samples/credit-forms-patching-sample/rabobank_patch.xml | NULL | NULL | true |
The table includes the field is_patch. Since it is assumed that patches should be applied
to data already loaded into the database, we need to somehow separate the documents into groups. At first, the parsing and loading of the
original XML should be performed, and only then apply the patches to them. This will require the creation of two
Job. The first Job will parse and load the main documents into the database. The second will apply patches to them. The field name can be anything.
More information on how to create a Job can be found here.
Examples of documents that will be used as patches for existing tables:
DeutscheBank:
<?xml version="1.0" encoding="UTF-8"?>
<UpdateInfo>
<ApplicantInfo>
<FullName>
<FirstName>Sofia</FirstName>
<LastName>Lorenzo</LastName>
</FullName>
<DateOfBirth>1992-03-24</DateOfBirth>
<MaritalStatus>Single</MaritalStatus>
<TaxIdentificationNumber>545-56-7190</TaxIdentificationNumber>
<ContactInfo>
<EmailAddress>sofia.newmail@example.com</EmailAddress>
<PhoneNumber>+39 02 51821810</PhoneNumber>
</ContactInfo>
</ApplicantInfo>
</UpdateInfo>
Barclays:
<?xml version="1.0" encoding="UTF-8"?>
<ContactInfoUpdate>
<Applicant>
<Name>
<First>Lisa</First>
<Last>Martin</Last>
</Name>
<DateOfBirth>1987-12-12</DateOfBirth>
<MaritalStatus>Married</MaritalStatus>
<TaxID>456-78-9012</TaxID>
<ContactInfo>
<Email>lisa.newmail@example.com</Email>
<Phone>+31 20 83115136</Phone>
</ContactInfo>
</Applicant>
</ContactInfoUpdate>
Rabobank:
<?xml version="1.0" encoding="UTF-8"?>
<LoanApplicationUpdate>
<Applicant>
<FullName>
<FirstName>John</FirstName>
<LastName>Smith</LastName>
</FullName>
<isMarried>TRUE</isMarried>
<DateOfBirth>1980-03-25</DateOfBirth>
<SocialSecurityNumber>987-65-4321</SocialSecurityNumber>
<ContactInformation>
<Email>john.smith.newmail@example.com</Email>
<Phone>+44 20 12345678</Phone>
</ContactInformation>
</Applicant>
</LoanApplicationUpdate>
As an example, we will be updating the fields:
phone_number,
email,
is_married
Overall Project View:
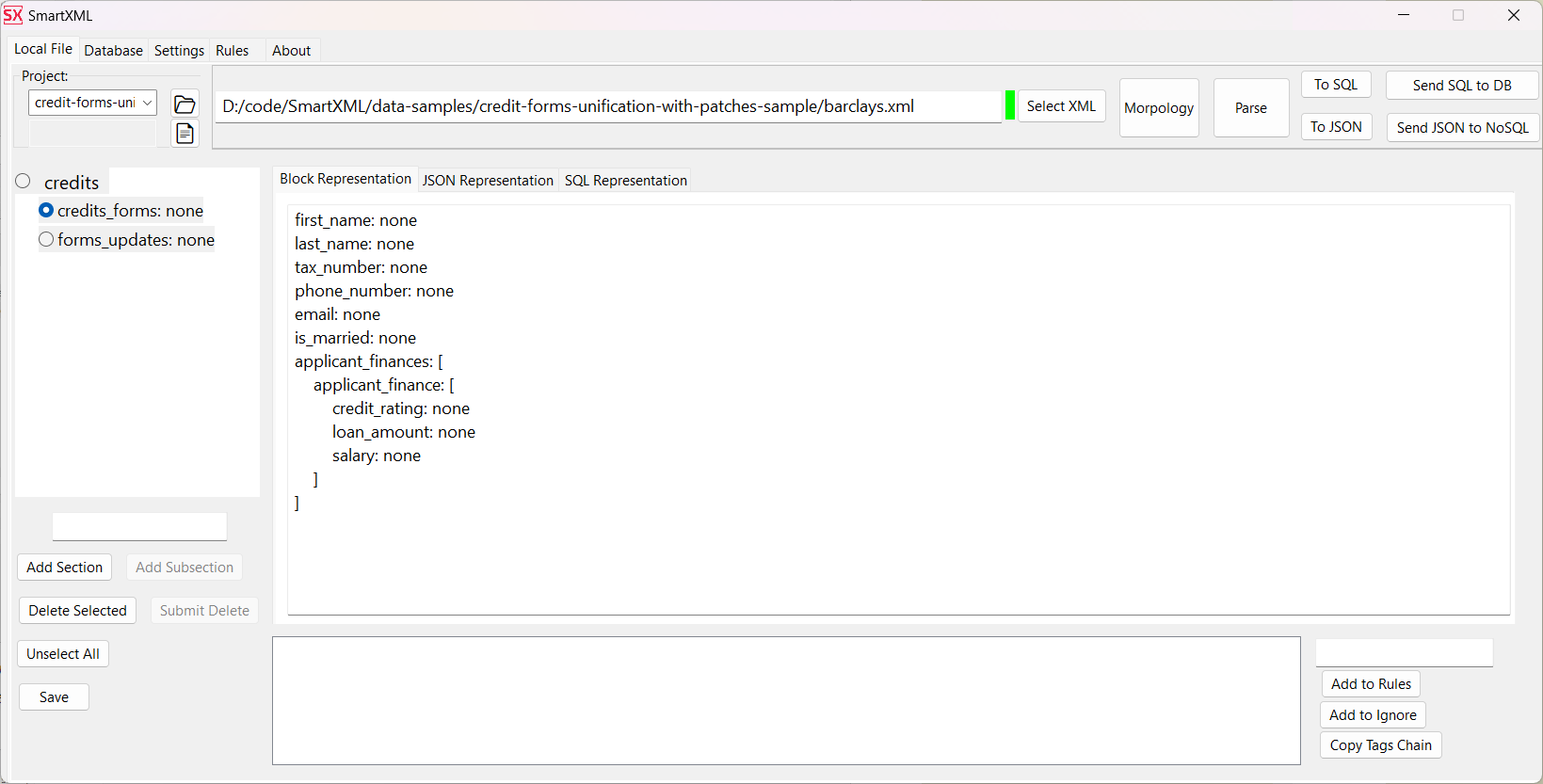
The structure describing the data for updating must have a field tag with a value like:
"update_tableNameForUpdating". In our case: tag: "update_credits_forms".
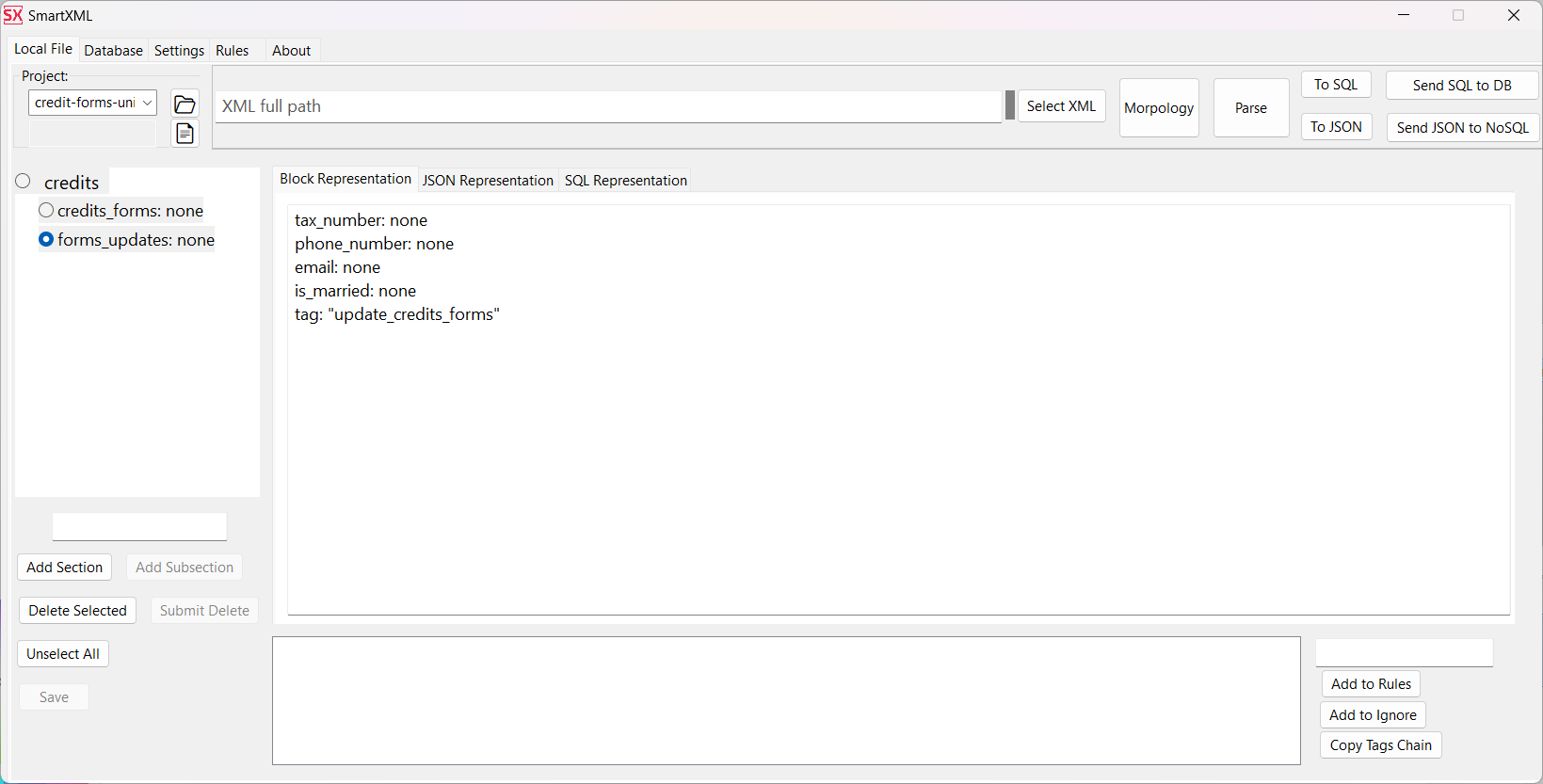
Uniqueness settings:
Rules ⮞ Database Constraints need to specify that
in the tables credits_forms and applicant_finances, the column tax_number is unique
(in case of uniqueness for a group of columns, you should specify their names separated by a space).
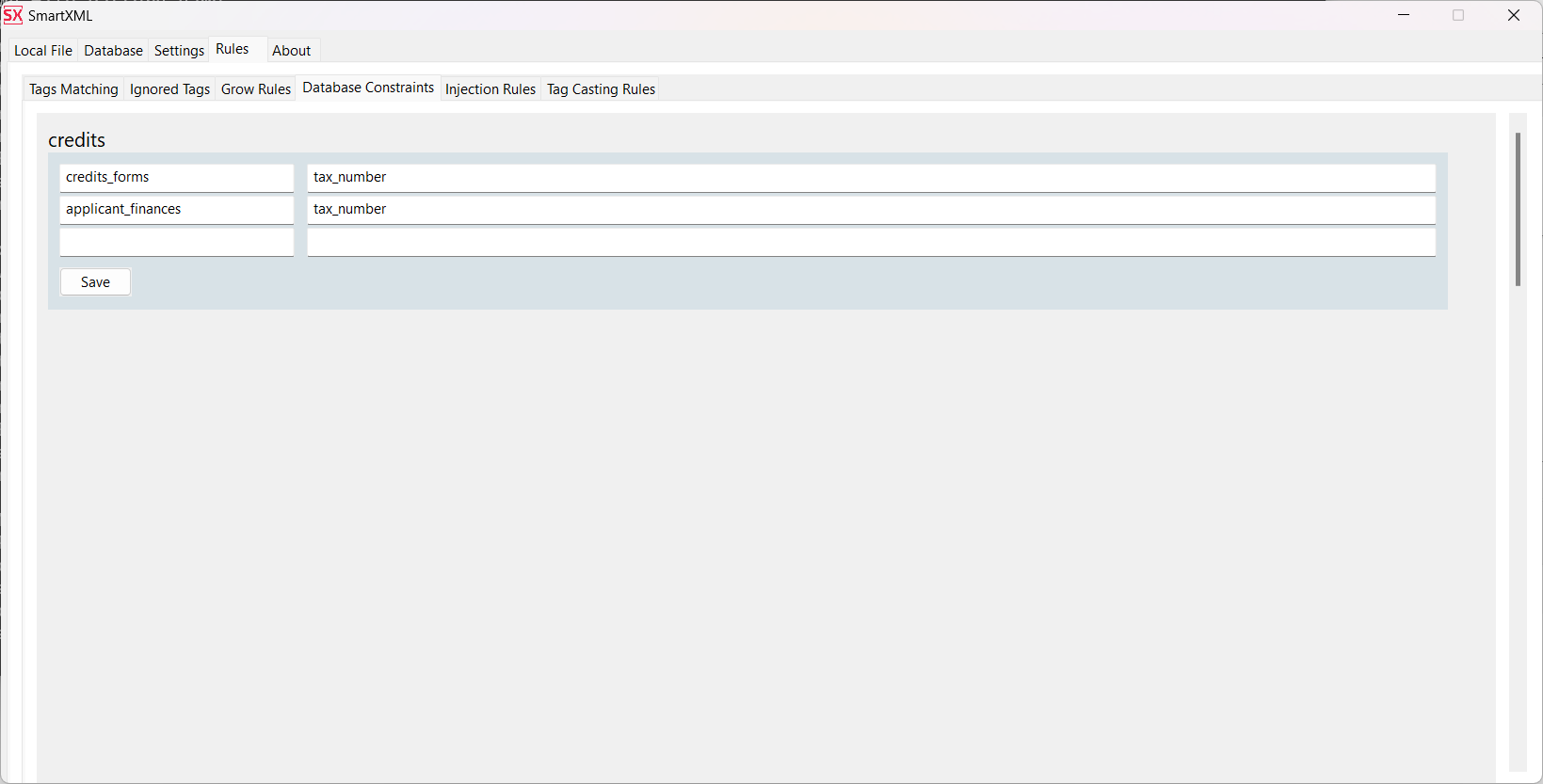
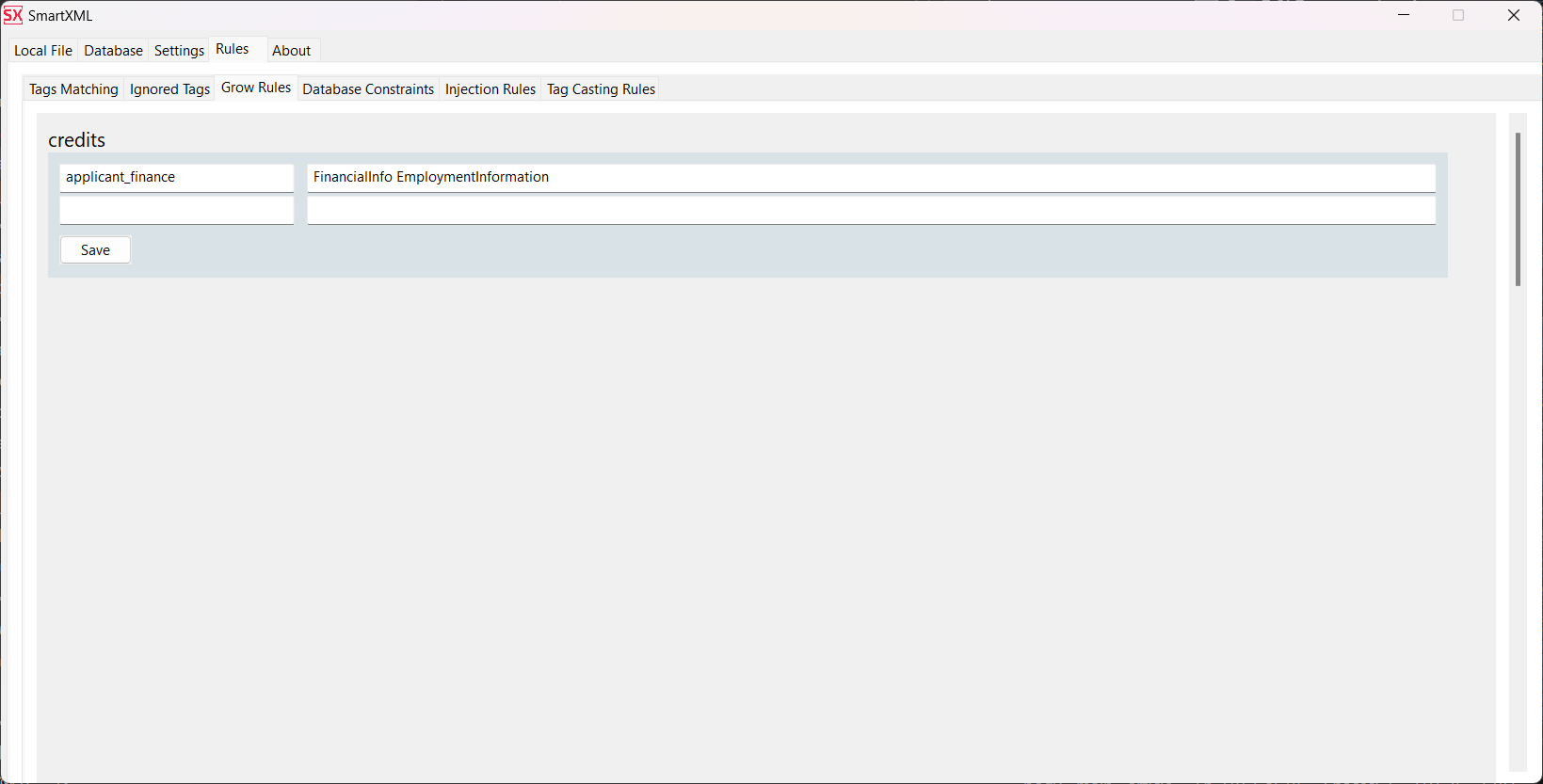
Also, it is necessary to specify the name of the node in the intermediate representation: applicant_finance, as well as its variations in XML:
FinancialInfo EmploymentInformation:
As seen from the intermediate representation, tax_number is located at the root. Specify that it
needs to be passed to each child of the intermediate representation from which the table will be generated:
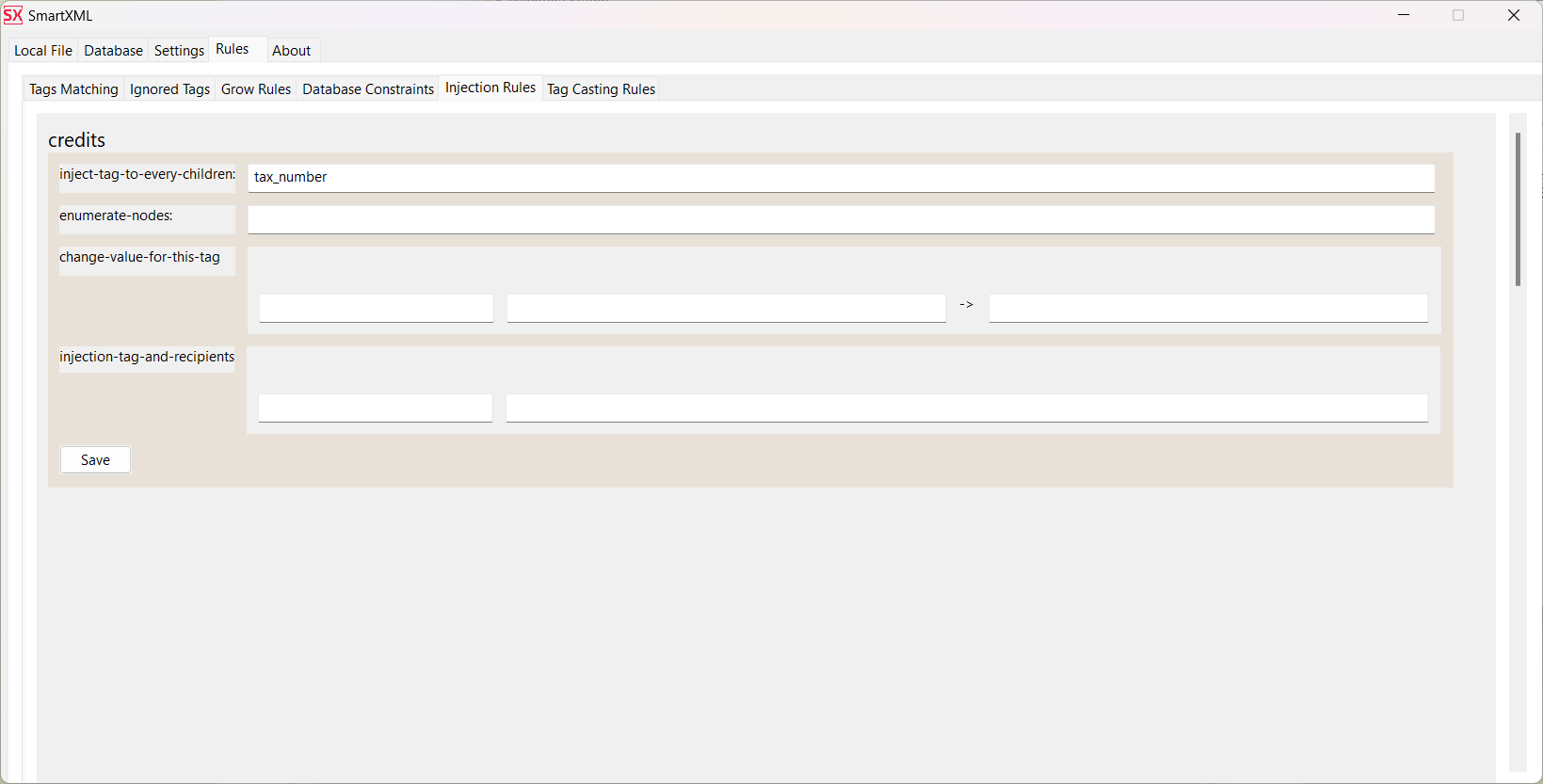
Table structures for extracting data from credit_forms and applicant_finances:
CREATE TABLE credits_forms (
"id" INTEGER PRIMARY KEY,
"first_name" Text,
"last_name" Text,
"tax_number" Text,
"phone_number" Text,
"email" Text,
"is_married" Text,
CONSTRAINT "unique_tax_number" UNIQUE (tax_number)
);
CREATE TABLE applicant_finances (
"id" INTEGER PRIMARY KEY,
"tax_number" Text,
"credit_rating" Text,
"loan_amount" Text,
"salary" Text,
CONSTRAINT "unique_tax_number" UNIQUE (tax_number)
);
Pay attention that in this example, all data is loaded into the database as text. Type conversion rules are covered in a separate article.
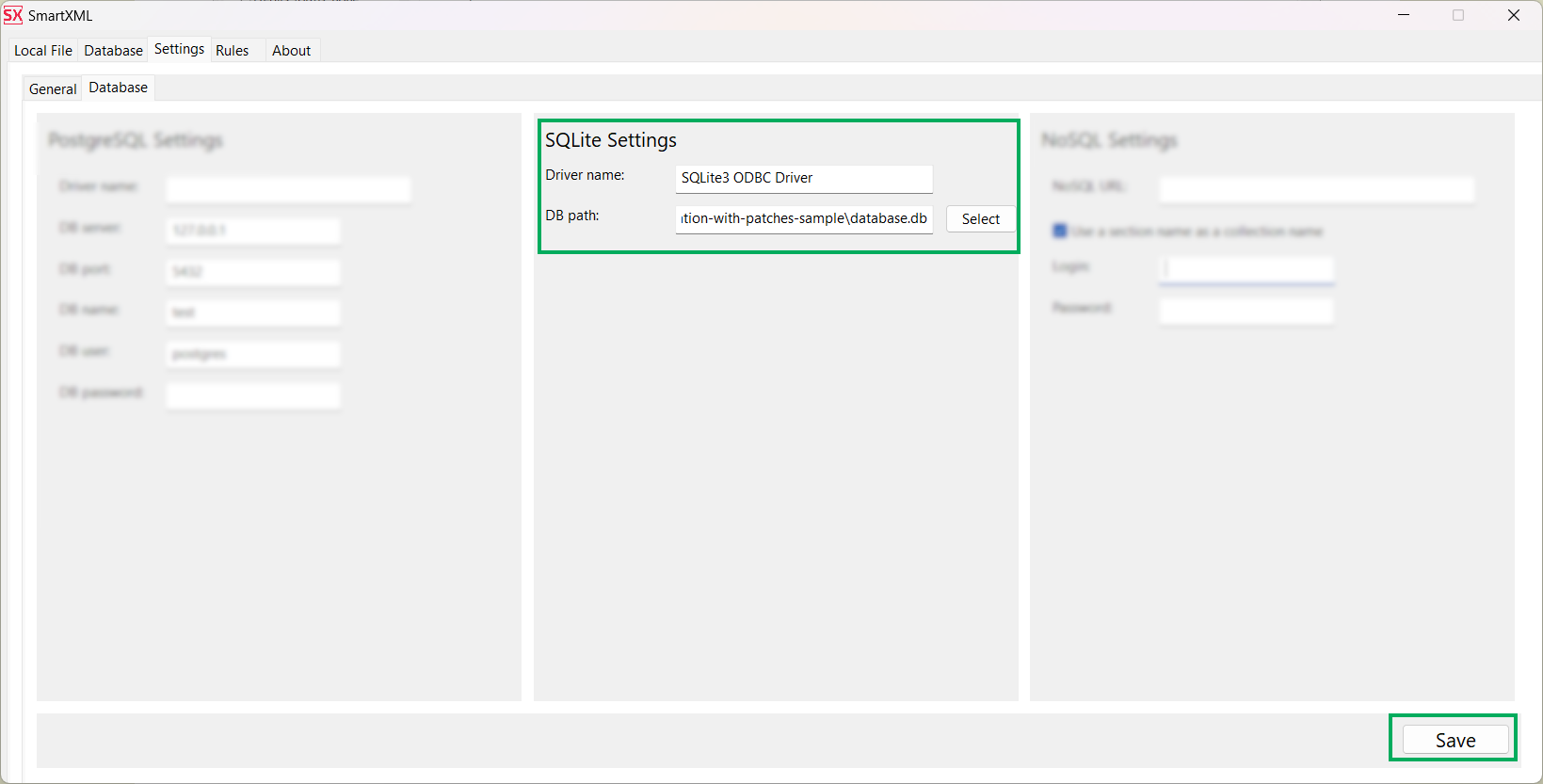
Configure the database connection on the Settings ⮞ Database tab.
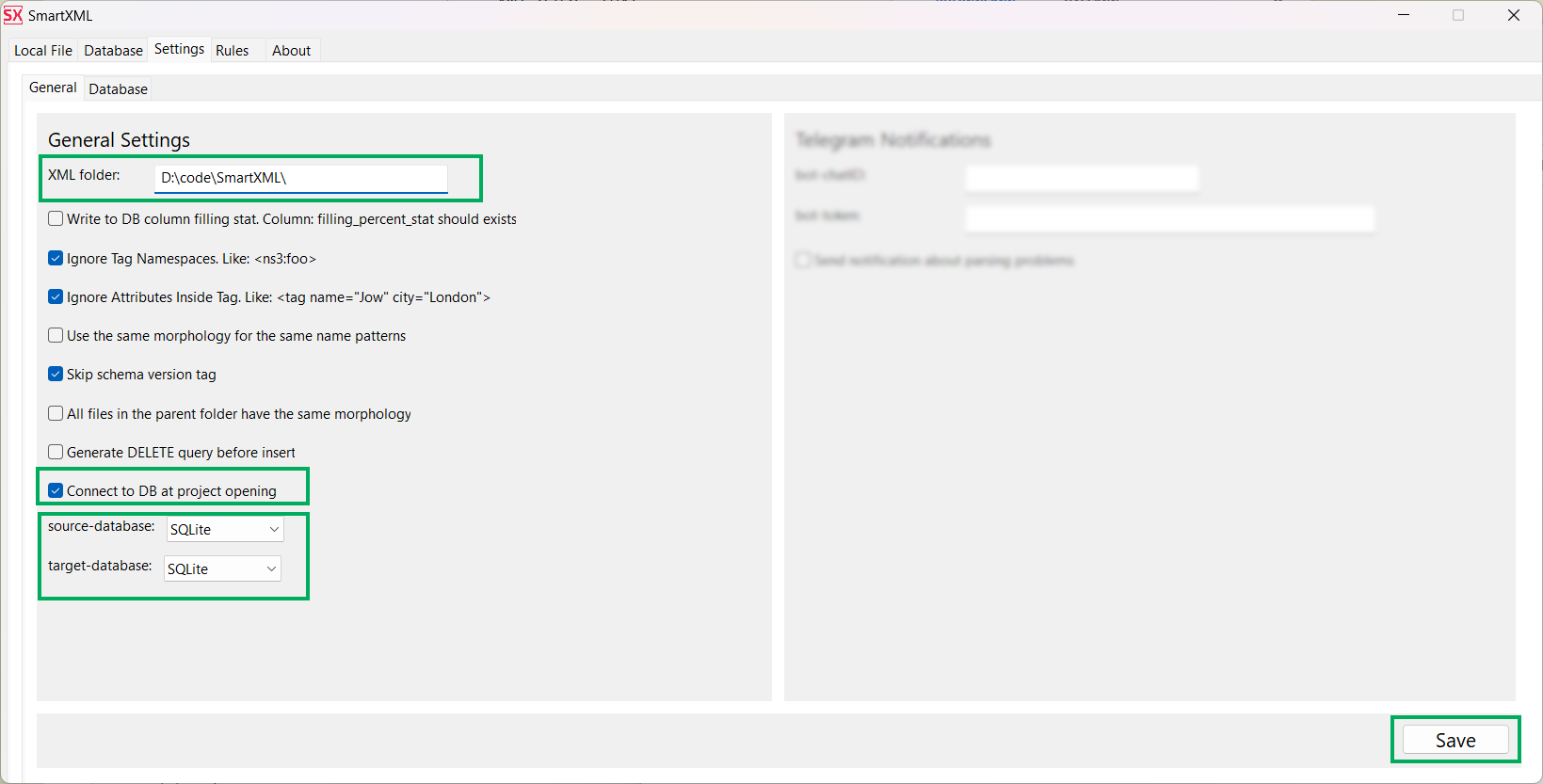
- On the Settings ⮞ General tab, specify the missing part of the path to the directory where the test XML files are located in the XML Folder field.
- Check the Connect to DB at project opening option (Requires restart).
-
Make sure that Source Database and Target Database are set to
SQLite. - Save the changes.
After restarting, on the Database tab, you can request the number of files awaiting processing by clicking Get XML Count.
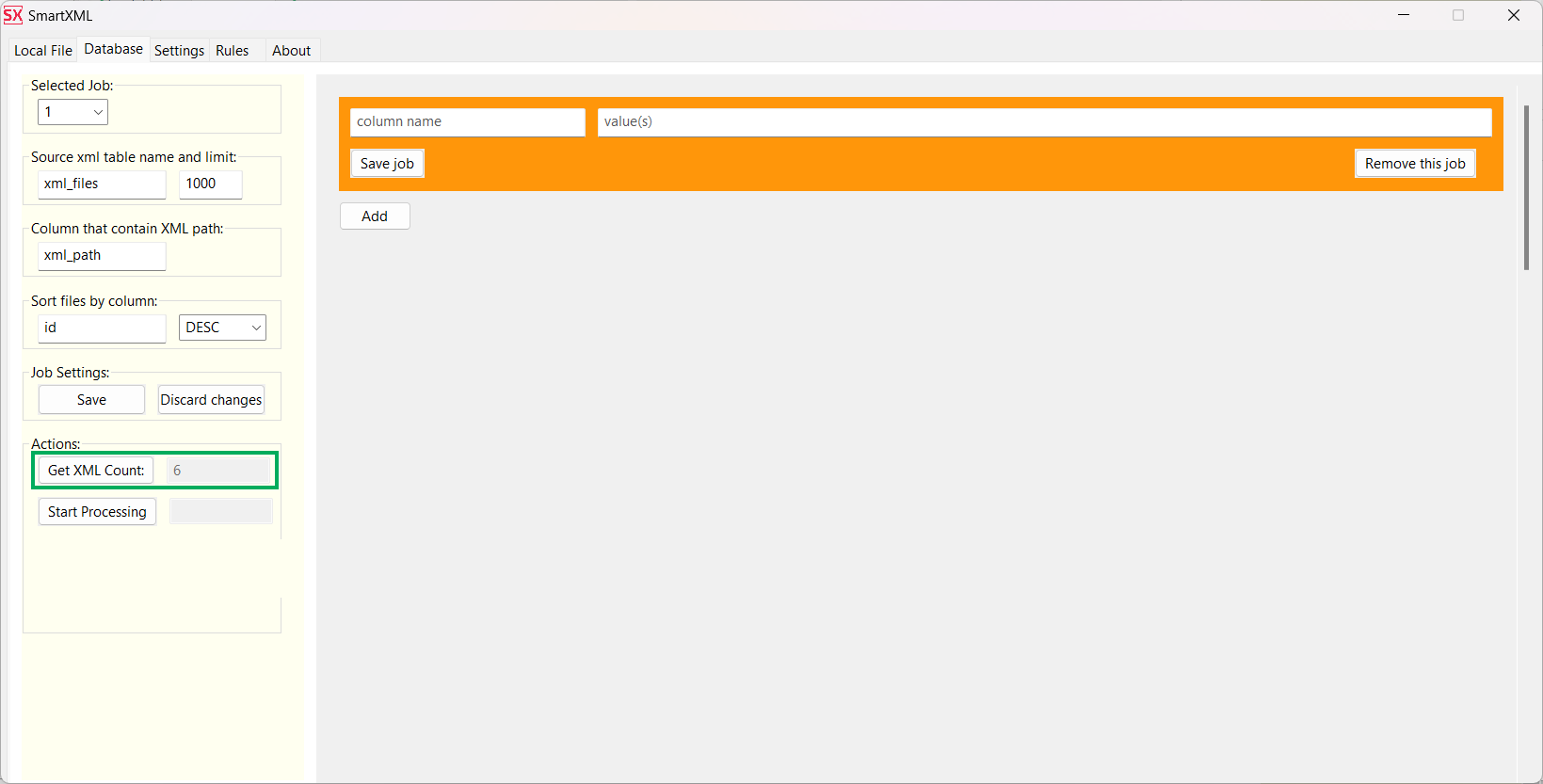
As mentioned earlier, it is necessary to process files containing complete data first and only then apply patches to them. For this, we will create two Job.
In the first Job, specify that you need to select data from the xml_files table where the is_patch column contains NULL. In the second one, NOT NULL
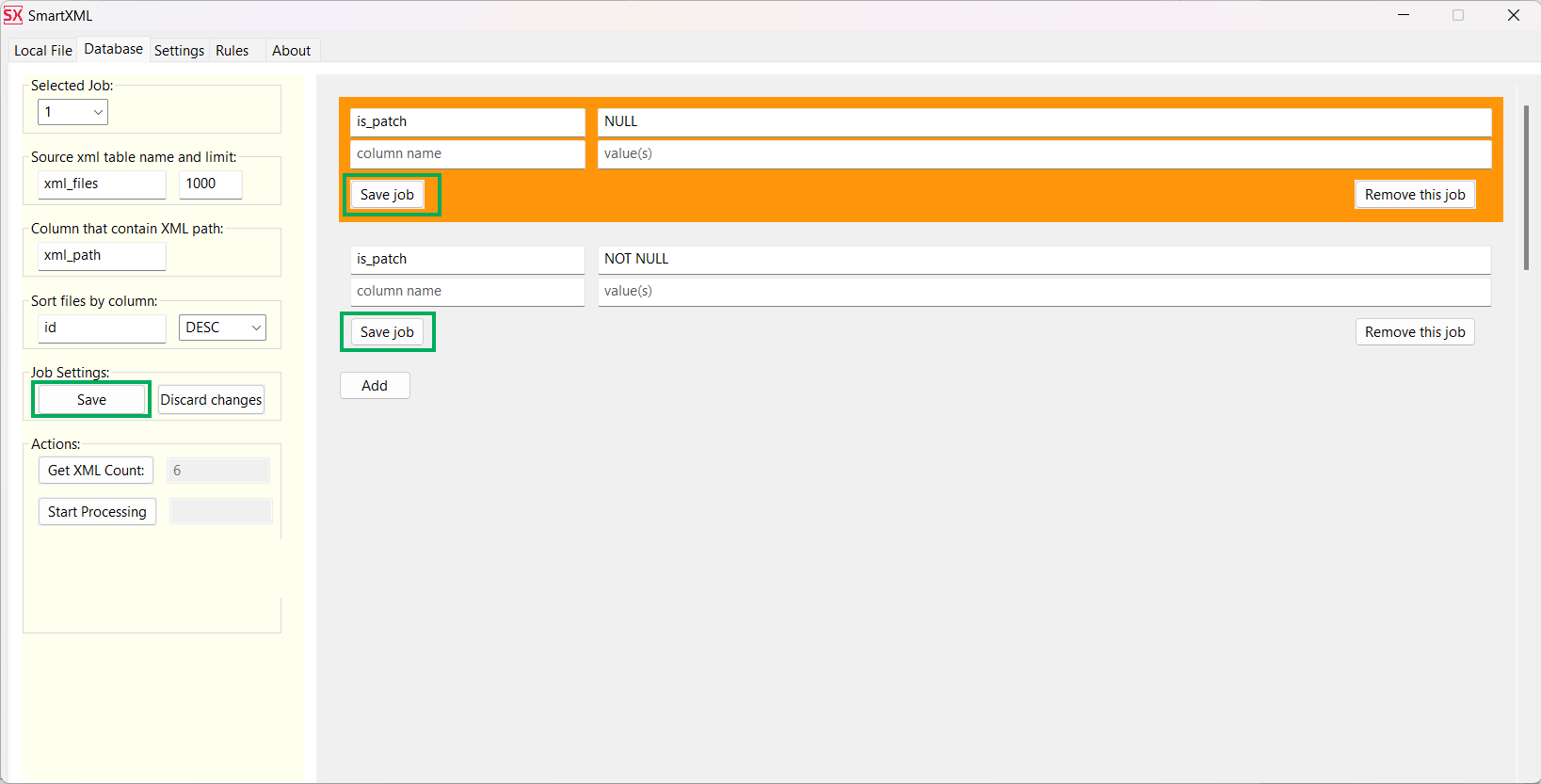
Be sure to save the changes for both the Job and the entire project.
Now, when you click on Get XML Count, it will show that the first Job has only 3 files to process.
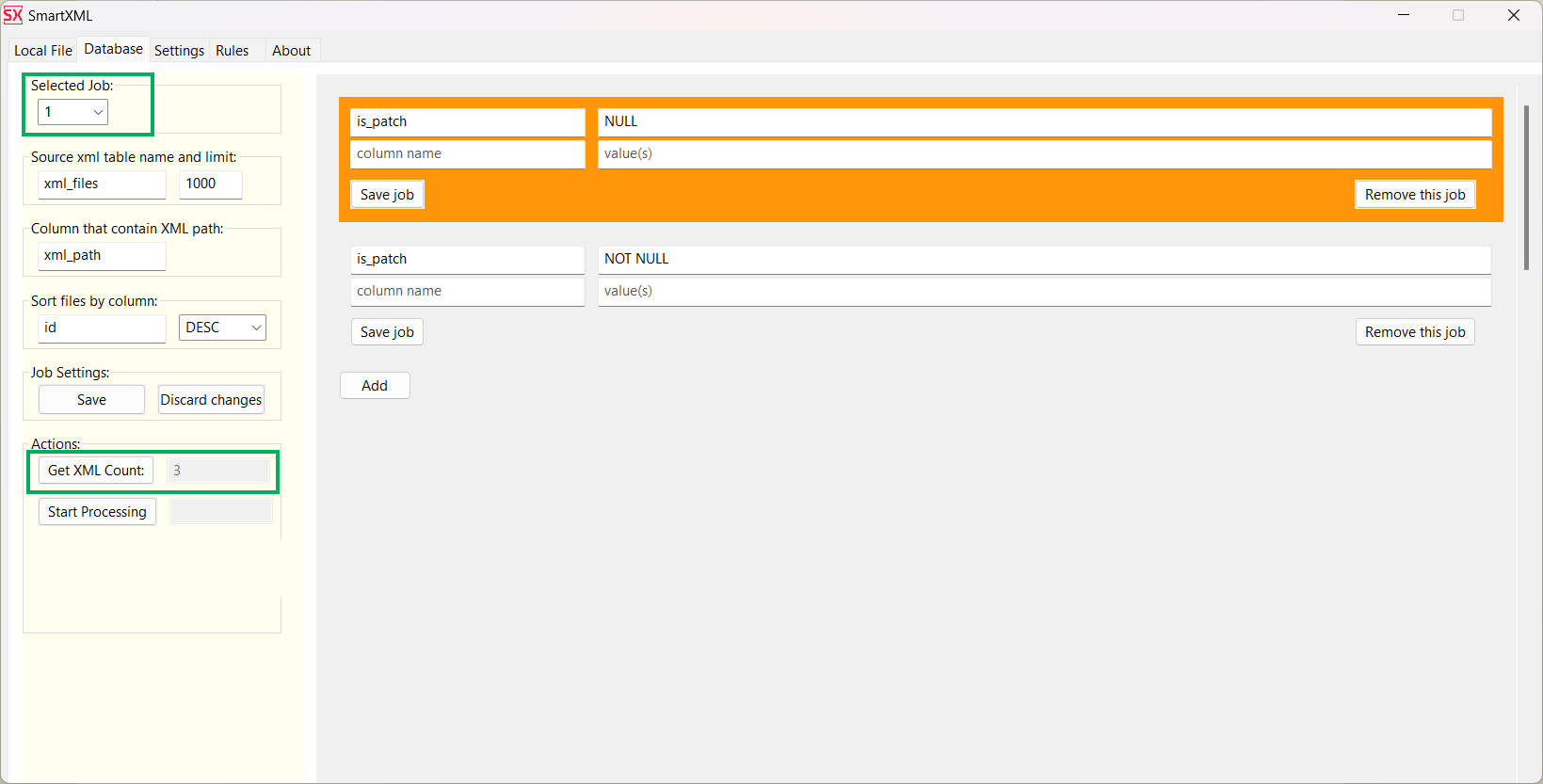
Clicking on Start Processing will initiate the processing.
Table structure after processing completion.
xml_files:
| id | xml_path | parsing_status | processed_date | is_patch |
|---|---|---|---|---|
| 1 | data-samples/credit-forms-patching-sample/barclays.xml | success | 2024-03-21 16:57 | NULL |
| 2 | data-samples/credit-forms-patching-sample/barclays_patch.xml | NULL | NULL | true |
| 3 | data-samples/credit-forms-patching-sample/deutschebank.xml | success | 2024-03-21 16:57 | NULL |
| 4 | data-samples/credit-forms-patching-sample/deutschebank_patch.xml | NULL | NULL | true |
| 5 | data-samples/credit-forms-patching-sample/rabobank.xml | success | 2024-03-21 16:57 | NULL |
| 6 | data-samples/credit-forms-patching-sample/rabobank_patch.xml | NULL | NULL | true |
credits_forms:
| id | first_name | last_name | tax_number | phone_number | is_married | |
|---|---|---|---|---|---|---|
| 1 | John | Smith | 987-65-4321 | +44 20 12345678 | john.smith@example.com | TRUE |
| 2 | Sofia | Lorenzo | 545-56-7190 | +39 02 98765432 | sofia.l@example.com | Married |
| 3 | Lisa | Martin | 456-78-9012 | +31 20 98765431 | lisa.m@example.com | Single |
applicant_finances:
| id | tax_number | credit_rating | loan_amount | salary |
|---|---|---|---|---|
| 1 | 987-65-4321 | 800 | 50000.00 | 75000.50 |
| 2 | 545-56-7190 | 710 | 42000.00 | 50000.75 |
| 3 | 456-78-9012 | 750 | 48000.00 | 71000 |
Switch to Job 2 and start processing XML files containing patches for the data:
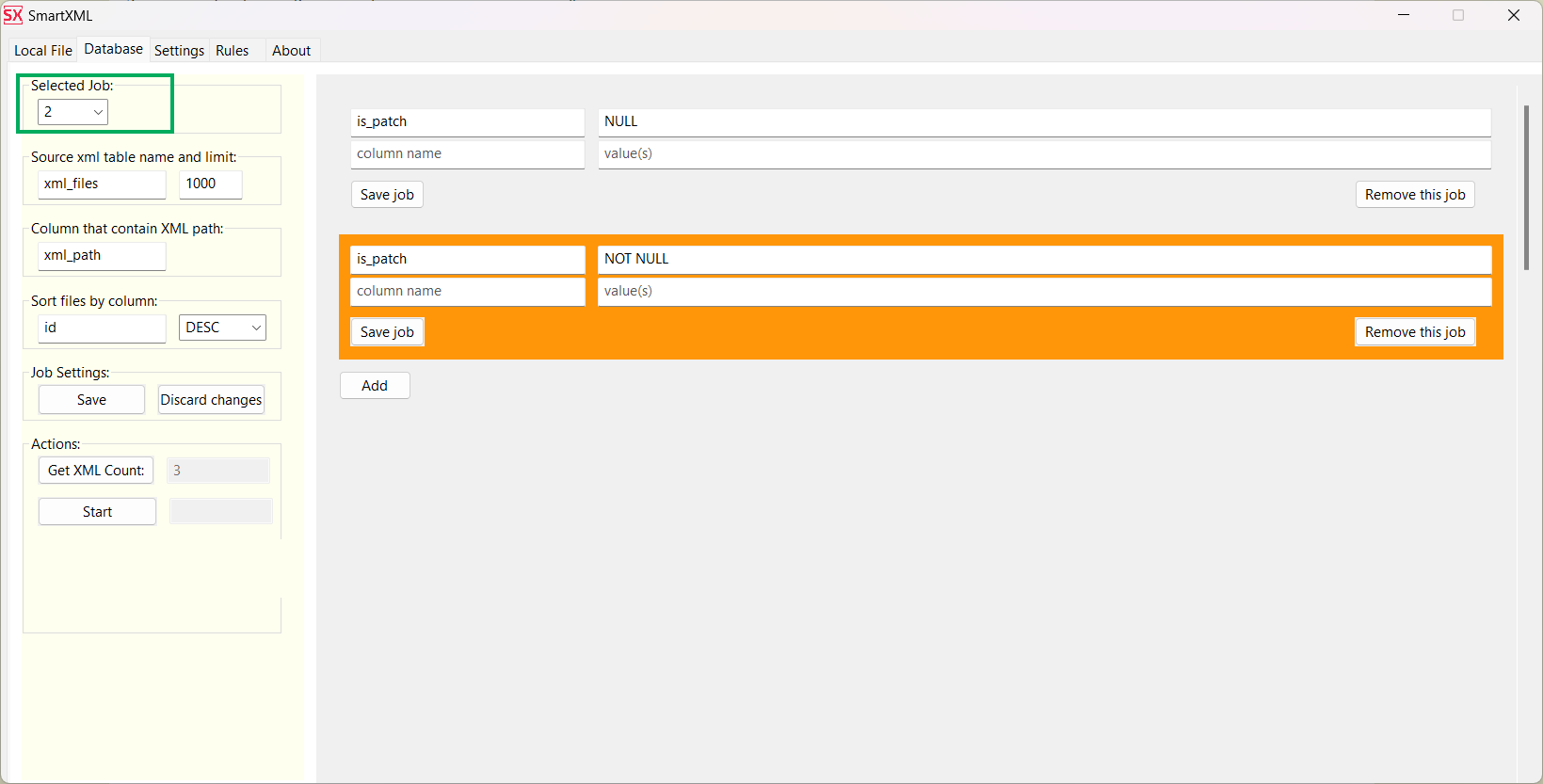
The final view of the xml_files table. All files have been processed:
| id | xml_path | parsing_status | processed_date | is_patch |
|---|---|---|---|---|
| 1 | data-samples/credit-forms-patching-sample/barclays.xml | success | 2024-03-10 17:52 | NULL |
| 2 | data-samples/credit-forms-patching-sample/barclays_patch.xml | success | 2024-03-10 17:52 | true |
| 3 | data-samples/credit-forms-patching-sample/deutschebank.xml | success | 2024-03-10 17:52 | NULL |
| 4 | data-samples/credit-forms-patching-sample/deutschebank_patch.xml | success | 2024-03-10 17:52 | true |
| 5 | data-samples/credit-forms-patching-sample/rabobank.xml | success | 2024-03-10 17:52 | NULL |
| 6 | data-samples/credit-forms-patching-sample/rabobank_patch.xml | success | 2024-03-10 17:52 | true |
Updated data in the table:
| id | first_name | last_name | tax_number | phone_number | is_married | |
|---|---|---|---|---|---|---|
| 1 | John | Smith | 987-65-4321 | +44 20 12345678 | john.smith.newmail@example.com | TRUE |
| 2 | Sofia | Lorenzo | 545-56-7190 | +39 02 51821810 | sofia.newmail@example.com | Single |
| 3 | Lisa | Martin | 456-78-9012 | +31 20 83115136 | lisa.newmail@example.com | Married |
Old data for comparison:
| id | first_name | last_name | tax_number | phone_number | is_married | |
|---|---|---|---|---|---|---|
| 1 | John | Smith | 987-65-4321 | +44 20 12345678 | john.smith@example.com | TRUE |
| 2 | Sofia | Lorenzo | 545-56-7190 | +39 02 98765432 | sofia.l@example.com | Single |
| 3 | Lisa | Martin | 456-78-9012 | +31 20 98765431 | lisa.m@example.com | Single |
Queries generated to update data in the credits_forms table:
UPDATE credits_forms
SET "phone_number" = '+39 02 51821810', "email" = 'sofia.newmail@example.com', "is_married" = 'Single'
WHERE "tax_number" ='545-56-7190';
UPDATE credits_forms
SET "phone_number" = '+31 20 83115136', "email" = 'lisa.newmail@example.com', "is_married" = 'Married'
WHERE "tax_number" = '456-78-9012';
UPDATE credits_forms
SET "phone_number" = '+44 20 12345678', "email" = 'john.smith.newmail@example.com'
WHERE "tax_number" = '987-65-4321';